
8.4. Reliability Data Analysis
8.4.2. How do you fit an acceleration model?
8.4.2.2. |
Maximum likelihood |
Under an acceleration assumption, however, all the cells contain samples from populations that have the same value of sigma (the slope does not change for different stress cells). Also, the \(T_{50}\) values are related to one another by the acceleration model; they all can be written using the acceleration model equation that includes the proper cell stresses.
To form the likelihood equation under the acceleration model assumption, simply rewrite each cell likelihood by replacing each cell \(T_{50}\) with its acceleration model equation equivalent and replacing each cell sigma with the same overall sigma. Then, multiply all these modified cell likelihoods together to obtain the overall likelihood equation.
Once the overall likelihood equation has been created, the maximum likelihood estimates (MLE) of sigma and the acceleration model parameters are the values that maximize this likelihood. In most cases, these values are obtained by setting partial derivatives of the log likelihood to zero and solving the resulting (non-linear) set of equations.
- The method can, in theory at least, be used for any distribution model and acceleration model and type of censored data.
- Estimates have "optimal" statistical properties as sample sizes (i.e., numbers of failures) become large.
- Approximate confidence bounds can be calculated.
- Statistical tests of key assumptions can be made using the likelihood ratio test. Some common tests are:
- the life distribution model versus another simpler model with fewer parameters (i.e., a 3-parameter Weibull versus a 2-parameter Weibull, or a 2-parameter Weibull versus an exponential),
- the constant slope from cell to cell requirement of typical acceleration models, and
- the fit of a particular acceleration model.
1. We generate survival curves for each cell. All plots and estimates are based on individual cell data, without the Arrhenius model assumption.
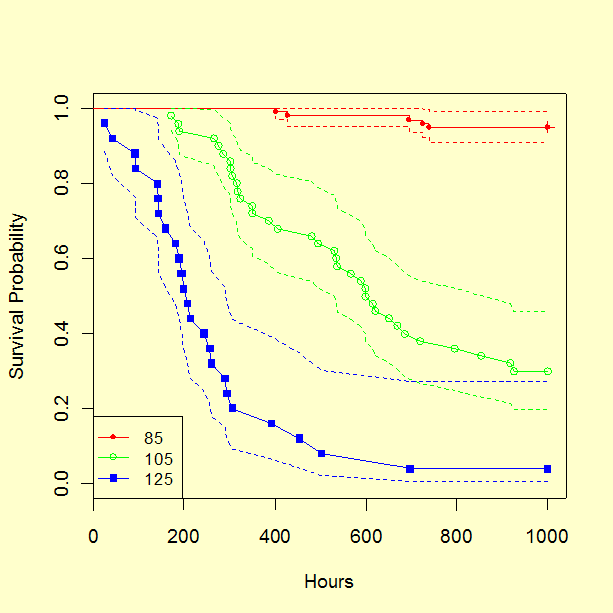
2. The results of lognormal survival regression modeling for the three data cells are shown below.
Cell 1 - 85 °C Parameter Estimate Stan. Dev z Value --------- -------- --------- ------- Intercept 8.891 0.890 9.991 ln(scale) 0.192 0.406 0.473 sigma = exp(ln(scale)) = 1.21 ln likelihood = -53.4
Cell 2 - 105 °C Parameter Estimate Stan. Dev z Value --------- -------- --------- ------- Intercept 6.470 0.108 60.14 ln(scale) -0.336 0.129 -2.60 sigma = exp(ln(scale)) = 0.715 ln likelihood = -265.2
Cell 3 - 125 °C Parameter Estimate Stan. Dev z Value --------- -------- --------- ------- Intercept 5.33 0.163 32.82 ln(scale) -0.21 0.146 -1.44 sigma = exp(ln(scale)) = 0.81 ln likelihood = -156.5
The cell ln likelihood values are -53.4, -265.2 and -156.5, respectively. Adding them together yields a total ln likelihood of -475.1 for all the data fit with separate lognormal parameters for each cell (no Arrhenius model assumption).
3. Fit the Arrhenius model to all data using MLE.
Parameter Estimate Stan. Dev z Value --------- -------- --------- ------- Intercept -19.906 2.3204 -8.58 l/kT 0.863 0.0761 11.34 ln(scale) -0.259 0.0928 -2.79 sigma = exp(ln(scale))Scale = 0.772 ln likelihood = -476.7
4. The likelihood ratio test statistic for the Arrhenius model fit (which also incorporates the single sigma acceleration assumption) is \(-2 \mbox{ ln } \lambda\), where \(\lambda\) denotes the ratio of the likelihood values with (\(L_0\)) and without (\(L_1\)) the Arrhenius model assumption so that $$ -2 \mbox{ ln } \lambda = -2 \mbox{ ln } (L_0 / L_1) = -2(\mbox{ln } L_0 - \mbox{ln } L_1) \, . $$ Using the results from steps 2 and 3, we have $$ -2 \mbox{ ln } \lambda = -2[-476.7 - (-475.1)] = 3.2 \, . $$ The degrees of freedom for the Chi-Square test statistic is 6 - 3 = 3, since six parameters were reduced to three under the acceleration model assumption. The chance of obtaining a value 3.2 or higher is 36.3 % for a Chi-Square distribution with 3 degrees of freedom, which indicates an acceptable model (no significant lack of fit).
This completes the Arrhenius model analysis of the three cells of data. If different cells of data have different voltages, then a new variable "\(\mbox{ln } V\)" could be added as an effect to fit the Inverse Power Law voltage model. In fact, several effects can be included at once if more than one stress varies across cells. Cross product stress terms could also be included by adding these columns to the spreadsheet and adding them in the model as additional "effects".
| Graphical Estimates | MLE | |||
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
Note that when there are a lot of failures and little censoring, the two methods are in fairly close agreement. Both methods are also in close agreement on the Arrhenius model results. However, even small differences can be important when projecting reliability numbers at use conditions. In this example, the CDF at 25 °C and 100,000 hours projects to 0.014 using the graphical estimates and only 0.003 using the MLE.
