
8.4. Reliability Data Analysis
8.4.2. How do you fit an acceleration model?
8.4.2.3. |
Fitting models using degradation data instead of failures |
This overview of degradation modeling assumes you have chosen a life distribution model and an acceleration model and offers an alternative to the accelerated testing methodology based on failure data, previously described. The following topics are covered.
More details can be found in Nelson (1990, pages 521-544) or Tobias and Trindade (1995, pages 197-203).
- A parameter \(D\), that can be measured over time, drifts monotonically (upwards, or downwards) towards a specified critical value \(DF\). When it reaches \(DF\), failure occurs.
- The drift, measured in terms of \(D\), is linear over time with a slope (or rate of degradation) \(R\), that depends on the relevant stress the unit is operating under and also the (random) characteristics of the unit being measured. Note: It may be necessary to define \(D\) as a transformation of some standard parameter in order to obtain linearity - logarithms or powers are sometimes needed.
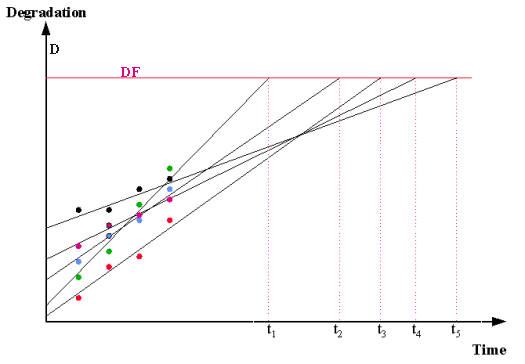
In many practical situations, \(D\) starts at 0 at time zero, and all the linear theoretical degradation lines start at the origin. This is the case when \(D\) is a "% change" parameter, or failure is defined as a change of a specified magnitude in a parameter, regardless of its starting value. Lines all starting at the origin simplify the analysis since we don't have to characterize the population starting value for \(D\), and the "distance" any unit "travels" to reach failure is always the constant \(DF\). For these situations, the degradation lines would look as follows.
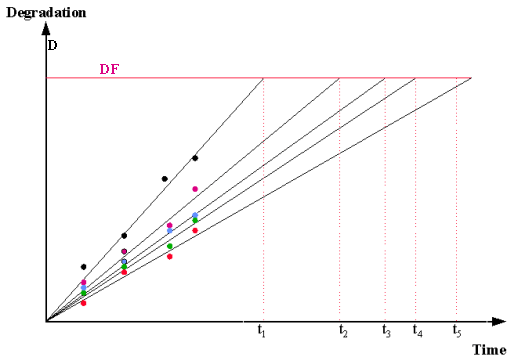
It is also common to assume the effect of measurement error, when reading values of \(D\), has relatively little impact on the accuracy of model estimates.
- Every degradation readout for every test unit contributes a data point. This leads to large amounts of useful data, even if there are very few failures.
- You don't have to run tests long enough to obtain significant numbers of failures.
- You can run low stress cells that are much closer to use conditions and obtain meaningful degradation data. The same cells would be a waste of time to run if failures were needed for modeling. Since these cells are more typical of use conditions, it makes sense to have them influence model parameters.
- Simple plots of degradation versus time can be used to visually test the linear degradation assumption.
- For many failure mechanisms, it is difficult or impossible to find a measurable parameter that degrades to a critical value in such a way that reaching that critical value is equivalent to what the customer calls a failure.
- Degradation trends may vary erratically from unit to unit, with no apparent way to transform them into linear trends.
- Sometimes degradation trends are reversible and a few units appear to "heal themselves" or get better. This kind of behavior does not follow typical assumptions and is difficult to model.
- Measurement error may be significant and overwhelm small degradation trends, especially at low stresses.
- Even when degradation trends behave according to assumptions and the chosen models fit well, the final results may not be consistent with an analysis based on actual failure data. This probably means that the failure mechanism depends on more than a simple continuous degradation process.
- As shown in the figures above, fit a line through each unit's degradation readings. This can be done by hand, but using a least squares regression program is better.
- Take the equation of the fitted line, substitute \(DF\) for \(Y\) and solve for \(X\). This value of \(X\) is the "projected time of fail" for that unit.
- Repeat for every unit in a stress cell until a complete sample of (projected) times of failure is obtained for the cell.
- Use the failure times to compute life distribution parameter estimates for a cell. Under the fairly typical assumption of a lognormal model, this is very simple. Take natural logarithms of all failure times and treat the resulting data as a sample from a normal distribution. Compute the sample mean and the sample standard deviation. These are estimates of \(\mbox{ln } T_{50}\) and \(\sigma\), respectively, for the cell.
- Assuming there are \(k\) cells with varying stress, fit an appropriate acceleration model using the cell \(\mbox{ln } T_{50}\) values, as described in the graphical estimation section. A single sigma estimate is obtained by taking the square root of the average of the cell \(\sigma^2\) estimates (assuming the same number of units each cell). If the cells have \(n_j\) units on test, where the \(n_j\) values are not all equal, use the pooled sum-of-squares estimate across all \(k\) cells calculated by
A More Accurate Regression Approach For the Case When \(D\) = 0 at time 0 and the "Distance To Fail" \(DF\) is the Same for All Units
Based on that readout alone, an estimate of the natural logarithm of the time to fail for that unit is $$ y_{ijk} = \mbox{ln } DF - \left( \mbox{ln } D_{ijk} - \mbox{ln } t_{jk} \right) \, . $$
This follows from the basic formula connecting linear degradation with failure time
by solving for (time of failure) and taking natural logarithms.
For an Arrhenius model analysis, with $$ t_f = A \cdot \mbox{exp}\left( \frac{\Delta H}{KT} \right) \, , $$ $$ y_{ijk} = a + b x_k \, , $$
with the \(x_k\) values equal to \(1/KT\). Here \(T\) is the temperature of the \(k\)-th cell, measured in Kelvin (273.16 + degrees Celsius) and \(K\) is Boltzmann's constant (8.617 × 10-5 in eV/ unit Kelvin). Use a linear regression program to estimate \(a = \mbox{ln } A\) and \(b = \Delta H\). If we further assume \(t_f\) has a lognormal distribution, the mean square residual error from the regression fit is an estimate of \(\sigma^2\) (with \(\sigma\) the lognormal sigma).
One way to think about this model is as follows: each unit has a random rate \(R\) of degradation. Since \(t_f = DF/R\), it follows from a characterization property of the normal distribution that if is lognormal, then \(R\) must also have a lognormal distribution (assuming \(DF\) and \(R\) are independent). After we take logarithms, \(\mbox{ln } R\) has a normal distribution with a mean determined by the acceleration model parameters. The randomness in \(R\) comes from the variability in physical characteristics from unit to unit, due to material and processing differences.
Note: The estimate of sigma based on this simple graphical approach might tend to be too large because it includes an adder due to the measurement error that occurs when making the degradation readouts. This is generally assumed to have only a small impact.
65 °C
|
|
|
|
| Unit 1 0.87 |
|
|
| Unit 2 0.33 |
|
|
| Unit 3 0.94 |
|
|
| Unit 4 0.72 |
|
|
| Unit 5 0.66 |
|
|
85 °C
|
|
|
|
| Unit 1 1.41 |
|
|
| Unit 2 3.61 |
|
|
| Unit 3 2.13 |
|
|
| Unit 4 4.36 |
|
|
| Unit 5 6.91 |
|
|
105 °C
|
|
|
|
| Unit 1 24.58 |
|
|
| Unit 2 9.73 |
|
|
| Unit 3 4.74 |
|
|
| Unit 4 23.61 |
|
|
| Unit 5 10.90 |
|
|
Note that one unit failed in the 85 °C cell and four units failed in the 105 °C cell. Because there were so few failures, it would be impossible to fit a life distribution model in any cell but the 105 °C cell, and therefore no acceleration model can be fit using failure data. We will fit an Arrhenius/lognormal model, using the degradation data.
Solution:
Fit the Arrhenius/lognormal equation, \(y_{ijk} = a + bx_{ijk}\), where $$ y_{ijk} = \mbox{ln } 30 - \left( \mbox{ln } DEG - \mbox{ln } TIME \right) $$ and $$ x_{ijk} = \frac{100000}{8.617(TEMP + 273.16)} \, . $$
The linear regression results are the following.
Parameter Estimate Stan. Dev t Value --------- -------- --------- ------- a -18.94337 1.83343 -10.33 b 0.81877 0.05641 14.52 Residual standard deviation = 0.5611 Residual degrees of freedom = 45
The Arrhenius model parameter estimates are: \(\mbox{ln } A\) = -18.94; \(\Delta H\) = 0.82. An estimate of the lognormal sigma is \(\sigma\) = 0.56.
The analyses in this section can can be implemented using both Dataplot code and R code.
