
|
|
CHI SQUARE GOODNESS OF FIT TESTName:
NOTE: This command has been replaced with the unified GOODNESS OF FIT command.
The primary advantage of the chi square goodnes of fit test is that it is quite general. It can be applied for any distribution, either discrete or continuous, for which the cumulative distribution function can be computed. Dataplot supports the chi-square goodness of fit test for all distributions for which it supports a CDF function. There are two primary disadvantages:
In order to apply the chi-square goodness of fit test, any shape parameters must be specified. For example,
WEIBULL CHI-SQUARE GOODNESS OF FIT TEST Y The name of the distributional parameter for families is given in the list below. Location and scale parameters can be specified generically with the following commands:
LET CHSSCALE = <value> The location and scale parameters default to 1 if not specified. Dataplot supports the chi-square goodness of fit test for either binned or unbinned data. For unbinned data, Dataplot automatically generates binned data using the same rule as for histograms. That is, the class width is 0.3*s where s is the sample standard devition. The upper and lower limits are the mean plus or minus 6 times the sample standard deviation (any zero frequency bins in the tails are omitted). As with the HISTOGRAM command, you can override these defaults using the CLASS WIDTH, CLASS UPPER, and CLASS LOWER commands. Pre-binned data can be specicied in two ways. If your bins are of equal size, then you specify a single X variable that contains the mid-points of the bins. If your bins may be of unequal size, then two X variables are given. The first contains the lower limit of each bin and the second contains the upper limit of each bin. Unequal bin sizes usually result from combining classes with small (less than 5) expected frequency.
where <y> is a response variable; <dist> is one of the following distributions: This syntax is used for the case where you have unbinned data.
where <y> is a variable of pre-computed frequencies; <x> is a variable containing the mid-points of the bins; <dist> is as above; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used for the case where you have binned data with equal size bins.
where <y> is a variable of pre-computed frequencies; <x1> is a variable containing the lower limits of the bins; <x2> is a variable containing the upper limits of the bins; <dist> is as above; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax is used for the case where you have binned data with unequal size bins.
NORMAL CHI-SQUARE GOODNESS OF FIT TEST Y SUBSET GROUP > 1 CAUCHY CHI-SQUARE GOODNESS OF FIT TEST Y LOGNORMAL CHI-SQUARE GOODNESS OF FIT TEST X EXTREME VALUE TYPE 1 CHI-SQUARE GOODNESS OF FIT TEST X LET LAMBDA = 0.2 TUKEY LAMBDA CHI-SQUARE GOODNESS OF FIT TEST X
SET MINMAX = 1
LET LAMBDA = 3
NORMAL CHI-SQUARE GOODNESS OF FIT TEST Y X
EV1 and GUMBEL are synonyms for EXTREME VALUE TYPE 1. FATIGUE LIFE is a synonym for FL. RECIPROCAL INVERSE GAUSSIAN is a synonym for RIG. IG is a synonym for INVERSE GAUSSIAN. The word TEST is optional. CHI-SQUARE, CHISQUARE, and CHI SQUARE can all be used.
read zarr13.dat y . let m = mean y let s = standard deviation y let chsloc = m let chsscale = s normal chi-square goodness of fit test y The following output is generated.
************************************************
** normal chi-square goodness of fit test y **
************************************************
CHI-SQUARED GOODNESS OF FIT TEST
NULL HYPOTHESIS H0: DISTRIBUTION FITS THE DATA
ALTERNATE HYPOTHESIS HA: DISTRIBUTION DOES NOT FIT THE DATA
DISTRIBUTION: NORMAL
SAMPLE:
NUMBER OF OBSERVATIONS = 195
NUMBER OF NON-EMPTY CELLS = 20
NUMBER OF PARAMETERS USED = 2
TEST:
CHI-SQUARED TEST STATISTIC = 5.506083
DEGREES OF FREEDOM = 17
CHI-SQUARED CDF VALUE = 0.004063
ALPHA LEVEL CUTOFF CONCLUSION
10% 24.76903 ACCEPT H0
5% 27.58711 ACCEPT H0
1% 33.40867 ACCEPT H0
CELL NUMBER, BIN MIDPOINT, OBSERVED FREQUENCY, AND
EXPECTED FRQUENCY
WRITTEN TO FILE DPST1F.DAT
Date created: 06/05/2001 |
Last updated: 12/11/2023 Please email comments on this WWW page to alan.heckert@nist.gov. | ||||||||||||||||||||||||||||||||||||
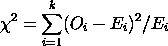
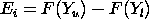
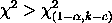
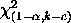 is the chi-square percent point function
with k - c degrees of freedom and a significance
level of
is the chi-square percent point function
with k - c degrees of freedom and a significance
level of