|
|
TWO WAY PLOTName:
This standard addresses the situation where there are two factors (material and laboratory) and there is a full factorial balanced design (i.e., each combination of material and laboratory is run with an equal number of replications). The E691 INTERLAB command generates the tables described in the standard. John Mandel proposed that a "phase 3" (see Analyzing Interlaboratory Data According to ASTM Standard E691) to examine the underlying mathematical model may sometimes be useful. The standard two-way additive ANOVA model is
where
The main row effect is \( R_{i} - M \) and the main column effect is \( C_{j} - M \). For the case where there is significant (in the sense of being much larger than the random error) interaction, Mandel introduced the "row-linear" model
That is, you essentially generate a linear fit for a specific laboratory across the various materials. This model effectively partitions the \( d^{*}_{ij} \) into a "systematic" and a "random" component
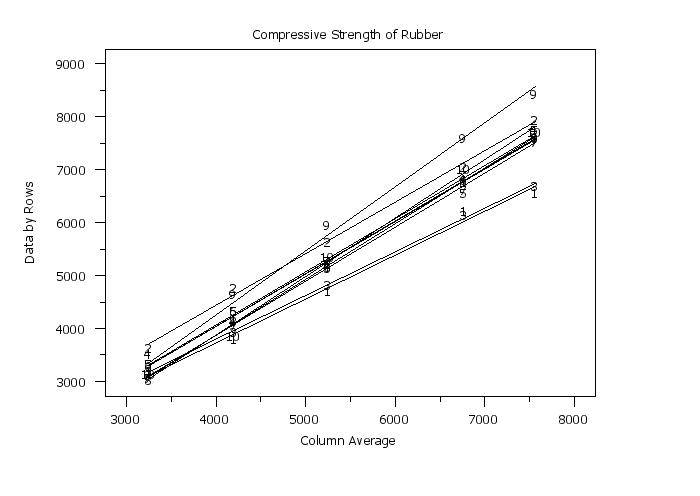
where \( d_{ij} \) is the random component and the rest is the systematic component. If the row-linear model is appropriate, then the systematic component should be much larger than the random component. Essentially, the systematic component is fitting a linear function of each laboratory against the average of all laboratories. The \( B_{i} \) in the above equation are the slopes of the linear fits. This command generates a plot of the linear fits for each row. Specifically, for each lab i plot
That is, you plot a given laboratory's value against the average of all laboratories for each material. Alternatively you can plot (see Note section below)
That is, plot the deviations from the column average versus the column average. In either case, the fitted lines are overlaid on the data points. The fundamental linearity is the same in either version of the plot. If the row-linear model is appropriate, the points for each laboratory should be approximately linear. If the slopes are all approximately equal to one, this implies that the row-linear model reduces to the additive model. In addition, this command generates the following tables:
Similarly, you can create a "column linear" model
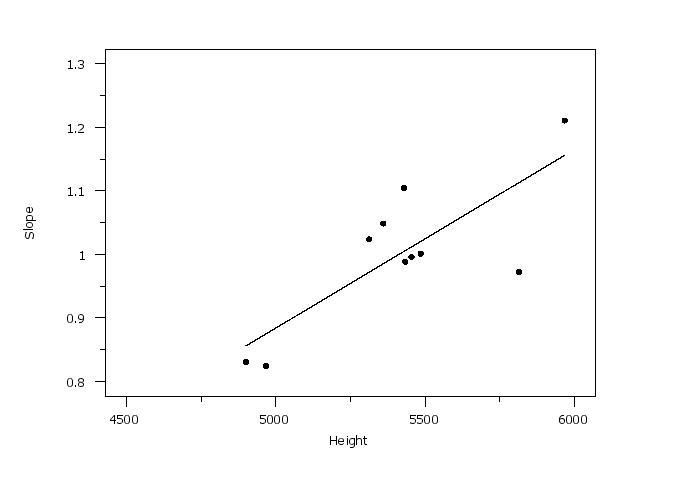
In the context of the E691 standard, the row linear model, where the rows denote laboratories, is typically of more interest. The remaining discussion will be in terms of the row linear model, but it applies equally to the column linear model (just interchange the roles of the rows and columns). Mandel goes on further to discuss "concurrent" models. In some cases, the slopes will exhibit a systematic pattern. If we generate a plot of the slopes versus the heights and this plot indicates a linear pattern, this is evidence of a concurrent model. When the concurrent model is appropriate, the fitted lines generated by the TWO WAY ROW PLOT command tend towards a common point. Call the y-coordinate of the common point y0. Then the concurrent model is
If y0 is zero, then the concurrent model reduces to the standard multiplicative model
Concurrent models can be useful when you have both row and column linearity. Note that the ANOVA table generated by this command further partitions the slopes sum of squares into "Concurrence" and "Non-Concurrence" parts. Although motivated by the E691 analysis, this plot can be used for any two factor data set from a full factorial design (i.e., all combinations of levels from the two factors are included). If there is replication within a cell, the mean of the replicates will be used. If there are any missing cells, an error will be reported and no plots or tables will be generated. The above is only a brief outline of row-linear models. For more detailed discussion and derivations, consult Mandel's publications in the Reference section below.
<SUBSET/EXCEPT/FOR qualification> where <y> is a response variable; <labid> is a variable that specifies the lab-id; <matid> is a variable that specifies the material-id; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax plots and fits the row-linear model.
<SUBSET/EXCEPT/FOR qualification> where <y> is a response variable; <labid> is a variable that specifies the lab-id; <matid> is a variable that specifies the material-id; and where the <SUBSET/EXCEPT/FOR qualification> is optional. This syntax plots and fits the column-linear model.
TWO WAY COLUMN PLOT Y LABID MATID TWO WAY ROW PLOT Y LABID MATID > 2
To reset the default, enter
Next, compare the "standard deviation of the slopes" to the standard deviations of the individual fits (i.e., the RESSD column in Table 1). If the standard deviation of the slopes is significantly larger than the RESSD values, this is evidence that there is a systematic effect for the laboratories and that the additive model is not applicable. The square of the correlation coefficients of the fits gives an indication of how much of the variablity is accounted for by the linear fit (i.e., the systematic component) and how much is random. If there is evidence of a systematic effect, then plot the fit slopes versus the fit heights. If this plots shows approximate linearity, then this is evidence for concurrence in the data. This is only a brief overview of the interpretation of row linear models. Consult the Mandel publications listed in the References section for a more complete discussion.
The following additional plots are recommended for the analysis of row linear models.
The following are written to dpst3f.dat:
This information is written to files to make it easier to generate some of the complimentary plots useful in analyzing row linear models.
To reset the default, enter the command
The factor variable (i.e., column 1 in tables 1 and 2) is often an integer value. The following command allows you to specify a different number of digits for this column
This command follows the same rules as the SET WRITE DECIMAL command and is typically set to 0. If you want this column to use the value given by the SET WRITE DECIMALS command (the default), enter
To restore the default of printing the fit table, enter
To restore the default of printing the column averages table, enter
To restore the default of printing the ANOVA table, enter
The sum of squares and mean sum of squares columns in the ANOVA table can be quite large. For this reason, you may want these to be written in exponential format. To specify the number of decimals for these columns, enter the command
This command follows the same rules as the SET WRITE DECIMAL command and is often set to -7. If you want this column to use the value given by the SET WRITE DECIMALS command (the default), enter
Mandel (1961), "Non-Additivity in Two-Way Analysis of Variance", Journal of the American Statistical Association, Vol. 56, pp. 878-888. Mandel (1995), "Structure and Outliers in Interlaboratory Studies", Journal of Testing and Evaluation, Vol. 23, No. 5, pp. 364-369. Mandel (1994), "Models and Interactions", Journal of Test and Evaluation, Vol. 19, No. 5, pp. 398-402. Mandel (1994), "Analyzing Interlaboratory Data According to ASTM Standard E691", Quality and Statistics: Total Quality Management, ASTM STP 1209, Kowalewski, Ed., American Society for Testing and Materials, Philadelphia, PA 1994, pp. 59-70. Mandel (1994), "Analysis of Two-Way Layouts", Chapman & Hall, New York. Mandel (1993), "Outliers in Interlaboratory Testing", Journal of Testing and Evaluation, Vol. 21, No. 2, pp. 132-135. Mandel (1991), "Evaluation and Control of Measurements", Marcel Dekker, Inc. Bradu and Gabriel (1978), "The Biplot as a Diagnostic Tool for Models of Two-Way Tables", Technometrics, Vol. 20, No. 1, pp. 47-68.
. Step 1: Read the data
.
dimension 40 columns
skip 25
read mandel8.dat y x1 x2
.
variable label y Compressive Strength
variable label x1 Lab-ID
variable label x2 Temperature
.
. Step 2: Define some default plot control settings
.
case asis
title case asis
title offset 2
label case asis
tic mark offset units screen
tic mark offset 3 3
.
. Step 3: Generate the plot
.
x1label Column Average
character blank all
line dash all
loop for k = 1 1 10
let kindex = (k-1)*2 + 1
let plot character kindex = ^k
let plot line kindex = blank
end of loop
.
set two way plot factor label value
set two way plot factor decimal 0
set two way plot anova table decimals -7
set write decimals 4
title Compressive Strength of Rubber
y1label Data by Rows
.
two way row plot y x1 x2
.
. Step 4: Generate the slope versus height plot
.
skip 1
read dpst1f.dat junk height slope
.
fit slope height
let htmin = minimum height
let htmax = maximum height
let function f = a0 + a1*x
.
character circle
character hw 1 0.75
character fill on
line blank dash
y1label Slope
x1label Height
title
.
xlimits 4500 6000
.
plot slope height and
plot f for x = htmin 0.1 htmax
The following output is generated
Parameters of Row-Linear Fit for Compressive Strength
-------------------------------------------------------------------------------------
Standard Error Correlation
Lab-ID Height Slope RESSD of Slope Coefficient
-------------------------------------------------------------------------------------
1 4900.0000 0.8305 150.6740 0.0424 0.9961
2 5814.0000 0.9721 106.3275 0.0299 0.9986
3 4967.0000 0.8240 53.0537 0.0149 0.9995
4 5485.0000 1.0012 182.6123 0.0514 0.9961
5 5433.0000 0.9885 188.1032 0.0530 0.9957
6 5454.0000 0.9960 84.8406 0.0239 0.9991
7 5312.0000 1.0239 92.6250 0.0261 0.9990
8 5360.0000 1.0486 50.7361 0.0143 0.9997
9 5967.0000 1.2107 210.1819 0.0592 0.9964
10 5429.0000 1.1045 173.7049 0.0489 0.9971
Standard Deviation of Slopes: 0.1149
Pooled Standard Deviation of Fit: 148.4192
Column Averages
---------------------------
Column
Temperature Average
---------------------------
-20 7567.5000
0 6772.5000
20 5252.5000
40 4209.5000
60 3258.5000
Mean of Column Means: 5412.1000
ANOVA Table for Row-Linear Fit
-----------------------------------------------------------------
Degrees of Sum of Mean
Source Freedom Squares Square
-----------------------------------------------------------------
Total 49 0.1329069E+09 0.2712385E+07
Rows 9 0.4751624E+07 0.5279583E+06
Column 4 0.1260615E+09 0.3151537E+08
Error 36 0.2093738E+07 0.5815939E+05
Residuals 27 0.5947629E+06 0.2202825E+05
Slopes 9 0.1498975E+07 0.1665528E+06
Concurrence 1 0.9485005E+06 0.9485005E+06
Non-Concurrence 8 0.5504746E+06 0.6880933E+05
Date created: 07/08/2015 |
Last updated: 12/04/2023 Please email comments on this WWW page to alan.heckert@nist.gov. | ||||||||||||||||||||||||||||||||||||||||||||||||