
|
|
VAN DER WAERDENName:
The standard ANOVA assumes that the errors (i.e., residuals) are normally distributed. If this normality assumption is not valid, an alternative is to use a non-parametric test. The most common non-parametric test for the one-factor model is the Kruskal-Wallis test. The Kruskal-Wallis test is based on the ranks of the data. The Van Der Waerden test converts the ranks to quantiles of the standard normal distribution (details given below). These are called normal scores and the test is computed from these normal scores. The advantage of the Van Der Waerden test is that it provides the high efficiency of the standard ANOVA analysis when the normality assumptions are in fact satisfied, but it also provides the robustness of the Kruskal-Wallis test when the normality assumptions are not satisfied. Let ni (i = 1, 2, ..., k) represent the sample sizes for each of the k groups (i.e., samples) in the data. Let N denote the sample size for all groups. Let Xij represent the ith value in the jth group. Then compute the normal scores as follows:
with R(Xij) and \( \phi \) denoting the rank of observation Xij and the normal percent point function, respectively. The average of the normal scores for each sample can then be computed as
The variance of the normal scores can be computed as
The Van Der Waerden test can then be defined as follows.
where <y> is the response (= dependent) variable; <x> is the factor (= independent) variable; and where the <SUBSET/EXCEPT/FOR qualification> is optional.
VAN DER WAERDEN Y X SUBSET X = 1 TO 4
The populations i and j seem to be different if the following inequality is satisfied:
with t and T1 denoting the t percent point function and the Van Der Waerden test statistic, respectively. Dataplot writes all the pairwise multiple comparisons to the file "dpst1f.dat" in the current directory.
The word TEST is optional
SKIP 25
READ SPLETT2.DAT Y MACHINE
SET WRITE DECIMALS 5
VAN DER WAERDEN Y MACHINE
The following output is generated.
Van Der Waerden (Normal Scores) One Factor Test
Response Variable: Y
Group-ID Variable: MACHINE
H0: Samples Come From Identical Populations
Ha: Samples Do Not Come From Identical Populations
Summary Statistics:
Total Number of Observations: 99
Number of Groups: 4
Variance of Normal Scores of Ranks 0.92890
Van Der Waerden Test Statistic Value: 39.78569
CDF of Test Statistic: 1.00000
P-Value: 0.00000
Percent Points of the Chi-Square Reference Distribution
-----------------------------------
Percent Point Value
-----------------------------------
0.0 = 0.000
50.0 = 2.366
75.0 = 4.108
90.0 = 6.251
95.0 = 7.815
97.5 = 9.348
99.0 = 11.345
99.9 = 16.266
Conclusions (Upper 1-Tailed Test)
----------------------------------------------
Alpha CDF Critical Value Conclusion
----------------------------------------------
10% 90% 6.251 Reject H0
5% 95% 7.815 Reject H0
2.5% 97.5% 9.348 Reject H0
1% 99% 11.345 Reject H0
Multiple Comparisons Table
---------------------------------------------------------------------------
I J |Abar(i)-Abar(j 90% CV 95% CV 99% CV
---------------------------------------------------------------------------
1 2 0.65906 0.35813 0.42803 0.56674
1 3 1.57550 0.35813 0.42803 0.56674
1 4 0.17816 0.35813 0.42803 0.56674
2 3 0.91644 0.35446 0.42364 0.56092
2 4 0.48089 0.35446 0.42364 0.56092
3 4 1.39733 0.35446 0.42364 0.56092
Date created: 01/05/2006 |
Last updated: 12/11/2023 Please email comments on this WWW page to alan.heckert@nist.gov. | ||||||||||||||||||||||||||||||||||||||||||||||||
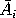 )
)