
|
|
TEST SENSITIVITYName:
The parameters N11, N12, N21, and N22 denote the counts for each category. Success and failure can denote any binary response. Dataplot expects "success" to be coded as "1" and "failure" to be coded as "0". Some typical examples would be:
In these examples, the "ground truth" is typically given as variable 1 while some estimator of the ground truth is given as variable 2. The test sensitivity is then N11/(N11+N12). That is, the test sensitivity is the conditional probability that variable 2 is a success given that variable 1 is a success. In the context of the first example above, the test sensitivity is the probability that the test detects the disease given that the disease is present.
<SUBSET/EXCEPT/FOR qualification> where <y1> is the first response variable; <y2> is the second response variable; <par> is a parameter where the computed test sensitivity is stored; and where the <SUBSET/EXCEPT/FOR qualification> is optional.
LET A = TEST SENSITIVITY Y1 Y2 SUBSET TAG > 2
let n = 1
.
let p = 0.2
let y1 = binomial rand numb for i = 1 1 100
let p = 0.1
let y2 = binomial rand numb for i = 1 1 100
.
let p = 0.4
let y1 = binomial rand numb for i = 101 1 200
let p = 0.08
let y2 = binomial rand numb for i = 101 1 200
.
let p = 0.15
let y1 = binomial rand numb for i = 201 1 300
let p = 0.18
let y2 = binomial rand numb for i = 201 1 300
.
let p = 0.6
let y1 = binomial rand numb for i = 301 1 400
let p = 0.45
let y2 = binomial rand numb for i = 301 1 400
.
let p = 0.3
let y1 = binomial rand numb for i = 401 1 500
let p = 0.1
let y2 = binomial rand numb for i = 401 1 500
.
let x = sequence 1 100 1 5
.
let a = test sensitivity y1 y2 subset x = 1
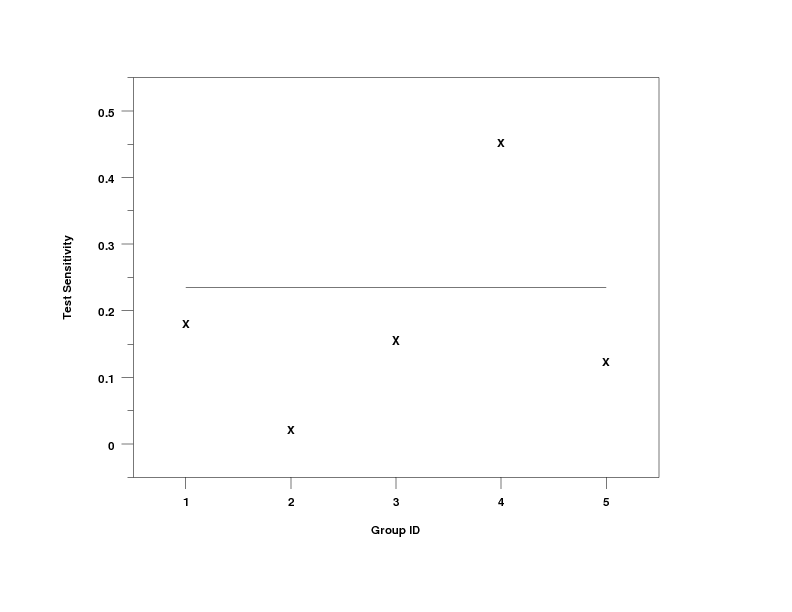
tabulate test sensitivity y1 y2 x
.
label case asis
xlimits 1 5
major xtic mark number 5
minor xtic mark number 0
xtic mark offset 0.5 0.5
ytic mark offset 0.05 0.05
y1label Test Sensitivity
x1label Group ID
character x blank
line blank solid
.
test sensitivity plot y1 y2 x
|
Privacy
Policy/Security Notice
NIST is an agency of the U.S.
Commerce Department.
Date created: 04/13/2007 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||