
|
|
TRIMMED MEAN STANDARD ERRORName:
Mosteller and Tukey (see Reference section below) define two types of robustness:
For location estimaors, the mean is the optimal estimator for Gaussian data. However, it is not resistant and it does not have robustness of efficiency. The trimmed mean estimator is both resistant and robust of efficiency. The standard error of the trimmed mean can be used to estimate the uncertainty of the trimmed mean estimate (and to create confidence intervals). The trimmed mean standard error is defined as:
where sw is the Winsorized standard deviation (enter HELP WINSORIZED STANDARD DEVIATION for details), \( \gamma_1 \) is the lower trimming fraction, \( \gamma_2 \) is the upper trimming fraction, and n is the sample size. Tukey and Mclaughlin suggest the following confidence interval for the trimmed mean:
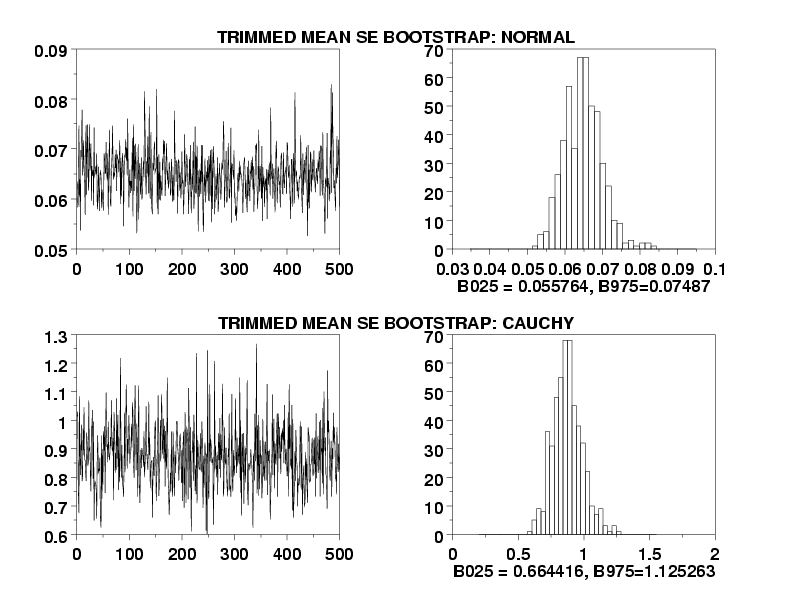
where alpha is the desired significance level, t is the student t-distribution, and \( g = [\gamma n] \) (the integer portion of the trimming fraction times the sample size). Note that we are assuming equal trimming on both tails (\( \gamma \) = .10 means we trim 10% on both tails). An alternative method for confidence intervals is to use the BOOTSTRAP TRIMMED MEAN PLOT command and use appropriate percentiles of the generated bootstrap trimmed mean values. Wilcox suggests a refinement of the standard bootstrap, which he calls he percentile t bootstrap, which has better performance than the standard bootstrap. Dataplot does not currently support this refinement.
<SUBSET/EXCEPT/FOR qualification> where <y1> is the response variable; <par> is a parameter where the computed trimmed mean standard error is stored; and where the <SUBSET/EXCEPT/FOR qualification> is optional.
LET A = TRIMMED MEAN STANDARD ERROR Y1 SUBSET TAG > 2
LET P2 = 10 LET A = TRIMMED MEAN STANDARD ERROR Y
Tukey and McLaughlin, "Less Vunerable Confidence and Significance Procedures for Location Based on a Single Sample: Trimming/Winsorization", Sankhya A, 25, pp. 331-352. Mosteller and Tukey (1977), "Data Analysis and Regression: A Second Course in Statistics", Addison-Wesley, pp. 203-209.
LET Y1 = NORMAL RANDOM NUMBERS FOR I = 1 1 100
LET Y2 = LOGISTIC RANDOM NUMBERS FOR I = 1 1 100
LET Y3 = CAUCHY RANDOM NUMBERS FOR I = 1 1 100
LET Y4 = DOUBLE EXPONENTIAL RANDOM NUMBERS FOR I = 1 1 100
LET A1 = TRIMMED MEAN STANDARD ERROR Y1
LET A2 = TRIMMED MEAN STANDARD ERROR Y2
LET A3 = TRIMMED MEAN STANDARD ERROR Y3
LET A4 = TRIMMED MEAN STANDARD ERROR Y4
Program 2:
MULTIPLOT 2 2
MULTIPLOT CORNER COORDINATES 0 0 100 100
MULTIPLOT SCALE FACTOR 2
X1LABEL DISPLACEMENT 12
.
LET Y1 = NORMAL RANDOM NUMBERS FOR I = 1 1 200
LET Y2 = CAUCHY RANDOM NUMBERS FOR I = 1 1 200
LET P1 = 10
LET P2 = 10
.
BOOTSTRAP SAMPLES 500
BOOTSTRAP TRIMMED MEAN STANDARD ERROR PLOT Y1
X1LABEL B025 = ^B025, B975=^B975
HISTOGRAM YPLOT
X1LABEL
.
BOOTSTRAP BIWEIGHT MIDVARIANCE PLOT Y1
X1LABEL B025 = ^B025, B975=^B975
HISTOGRAM YPLOT
.
END OF MULTIPLOT
.
JUSTIFICATION CENTER
MOVE 50 46
TEXT TRIMMED MEAN SE BOOTSTRAP: CAUCHY
MOVE 50 96
TEXT TRIMMED MEAN SE BOOTSTRAP: NORMAL
|
Privacy
Policy/Security Notice
NIST is an agency of the U.S.
Commerce Department.
Date created: 07/22/2002 | ||||||||||||||||||