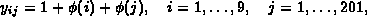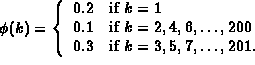

|
Main ANOVA Page |
SmLs02 Dataset |
|---|
Name:
SmLs02
Certification Method & Definitions
9 Treatments
201 Replicates/Cell
1809 Observations
1 Constant Leading Digit
Lower Level of Difficulty
Generated Data
 )
)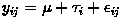
Even though the primary focus of these datasets is identification of problems caused by cancellation or accumulation error, these datasets may also identify errors in other aspects of ANOVA software such as computation of degrees of freedom or errors in the ANOVA table from other sources.
The formula used to generate this data is: