
|
Main Univ Page |
NumAcc2 Dataset |
NumAcc2 Results |
|---|
|
|
|
|
||||
|
Certification Method and Definitions
|
||||||
|---|---|---|---|---|---|---|
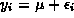
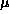 denotes the population mean,
denotes the population mean,  denotes the population standard deviation; and
denotes the population standard deviation; and 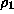 denotes the population lag-1 autocorrelation coefficient.
by the sample mean
denotes the population lag-1 autocorrelation coefficient.
by the sample mean
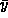 ; estimate
by the sample standard deviation
; estimate
by the sample standard deviation
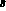 ; and estimate
by the sample lag-1 autocorrelation coefficient
; and estimate
by the sample lag-1 autocorrelation coefficient
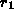 .
is defined as
.
is defined as
![ybar = (sum[i=1 to n] y(i)) / n](../gif/ybarequation.gif) is defined as
is defined as  - ybar)^2) / (n - 1)](../gif/sequation.gif) may have several definitions; we choose to use the
definition popular in time series analysis:
may have several definitions; we choose to use the
definition popular in time series analysis:
 - ybar)(y(i) - 1 - ybar) / (sum[1 to n](y(i) - ybar)^2)](../gif/r1equation.gif)