
2.6. Case studies
2.6.5. Uncertainty analysis for extinguishing fire
2.6.5.2. |
Create a calibration curve for the rotameter |
We plot the data in order to determine an appropriate model.
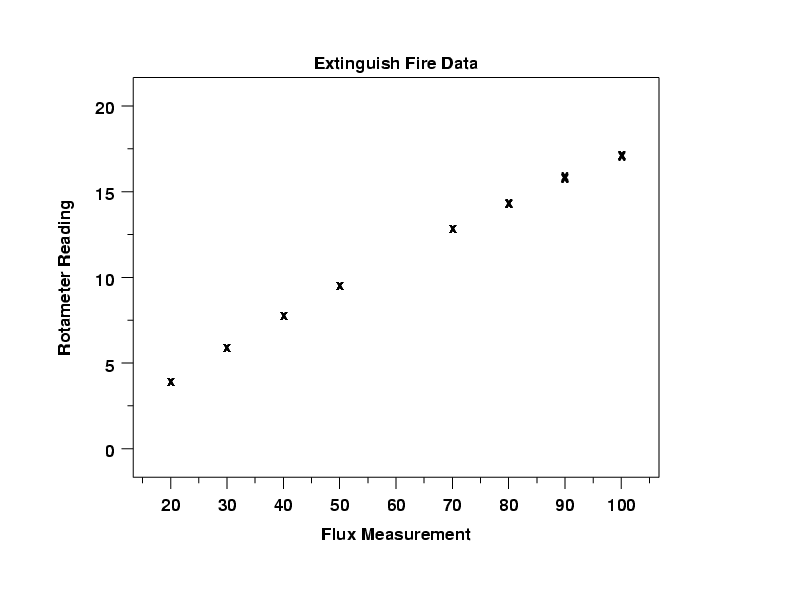
This plot indicates that a linear model might be approriate. It also shows that the replicated points show very little deviation. That is, for each X value it appears that there is a single point when in fact there are 10 points.
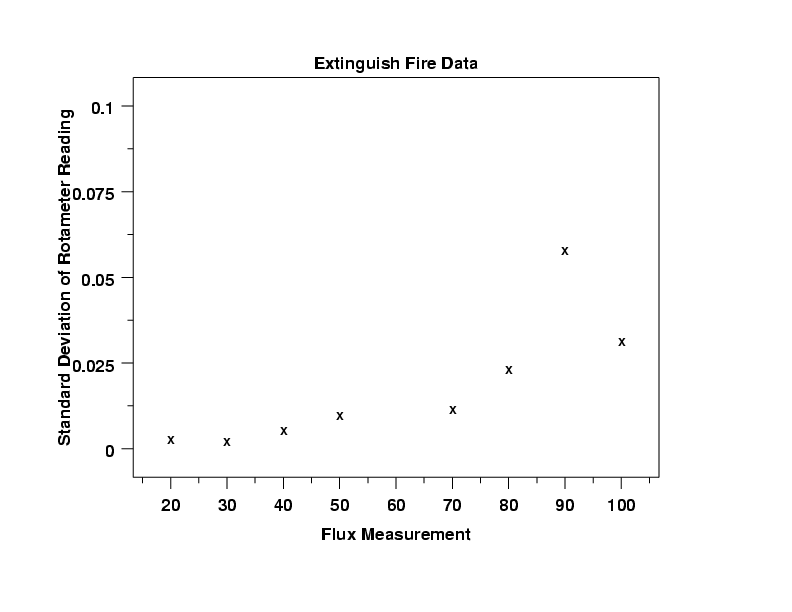
Although the standard deviations are quite small, the standard deviation plot shows the standard deviation increasing as the value of flux increases. The increase is particularly notable at flux equal 90.
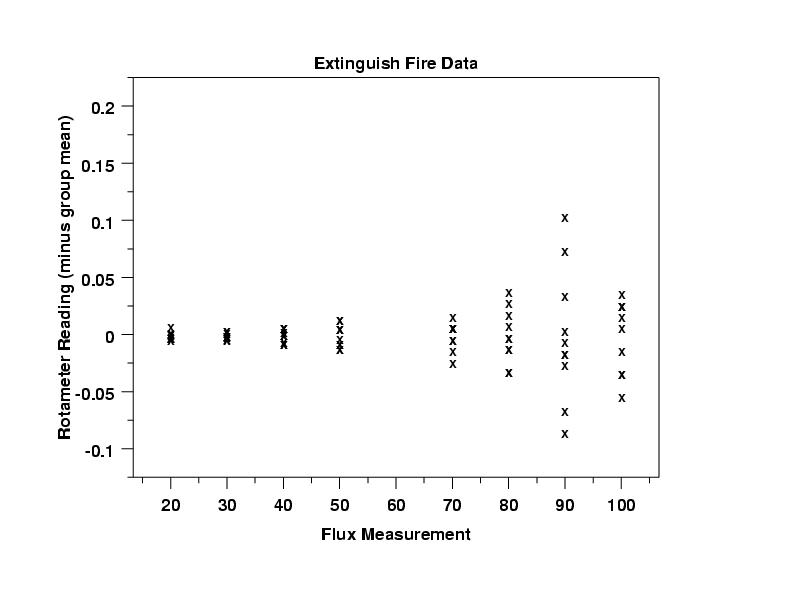
This plot shows clearly that the variation is increasing as the value of flux increases. This means that we may need to use weighting or transformations in developing the calibration curve.
LEAST SQUARES POLYNOMIAL FIT
SAMPLE SIZE N = 80
DEGREE = 1
REPLICATION CASE
REPLICATION STANDARD DEVIATION = 0.2554919757D-01
REPLICATION DEGREES OF FREEDOM = 72
NUMBER OF DISTINCT SUBSETS = 8
PARAMETER ESTIMATES (APPROX. ST. DEV.) T VALUE
1 A0 1.09419 (0.6796E-01) 16.
2 A1 0.164900 (0.1030E-02) 0.16E+03
RESIDUAL STANDARD DEVIATION = 0.2523804009
RESIDUAL DEGREES OF FREEDOM = 78
REPLICATION STANDARD DEVIATION = 0.0255491976
REPLICATION DEGREES OF FREEDOM = 72
LACK OF FIT F RATIO = 1256.5281 = THE 100.0000% POINT OF THE
F DISTRIBUTION WITH 6 AND 72 DEGREES OF FREEDOM
The linear fit generated the model
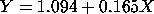
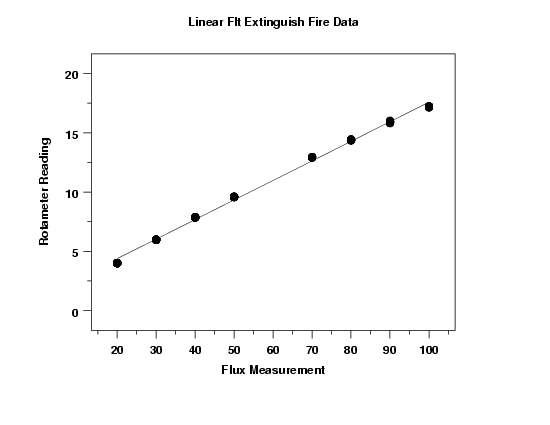
This plot indicates a good fit.
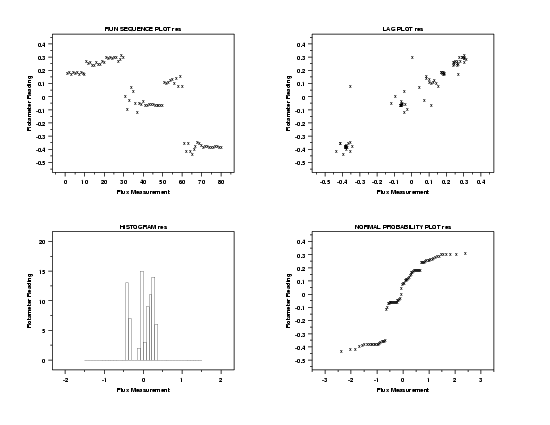
This 4-plot reveals serious violations of the regression assumptions. Specifically, the run sequence plot in the upper left corner shows a non-random pattern and it shows a violation of the assumption of constant location for the residuals. The lag plot in the upper right corner shows that the residuals have a strong autocorrelation, which violates the assumption of randomness for the residuals. When the randomness assumption is violated, the distributional plots (the histogram in the lower left corner and the normal probability plot in the lower right corner) are not meaningful.
LEAST SQUARES POLYNOMIAL FIT
SAMPLE SIZE N = 80
DEGREE = 2
REPLICATION CASE
REPLICATION STANDARD DEVIATION = 0.2554919757D-01
REPLICATION DEGREES OF FREEDOM = 72
NUMBER OF DISTINCT SUBSETS = 8
PARAMETER ESTIMATES (APPROX. ST. DEV.) T VALUE
1 A0 -0.144687 (0.2165E-01) -6.7
2 A1 0.217063 (0.8339E-03) 0.26E+03
3 A2 -0.434694E-03 (0.6847E-05) -63.
RESIDUAL STANDARD DEVIATION = 0.0347798578
RESIDUAL DEGREES OF FREEDOM = 77
REPLICATION STANDARD DEVIATION = 0.0255491976
REPLICATION DEGREES OF FREEDOM = 72
LACK OF FIT F RATIO = 14.1379 = THE 100.0000% POINT OF THE
F DISTRIBUTION WITH 5 AND 72 DEGREES OF FREEDOM
The fitted quadratic model is
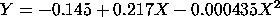
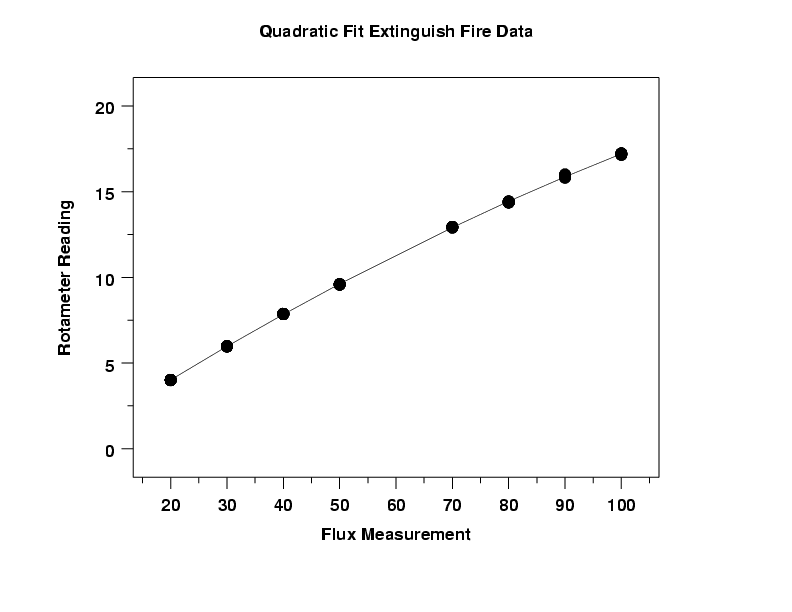
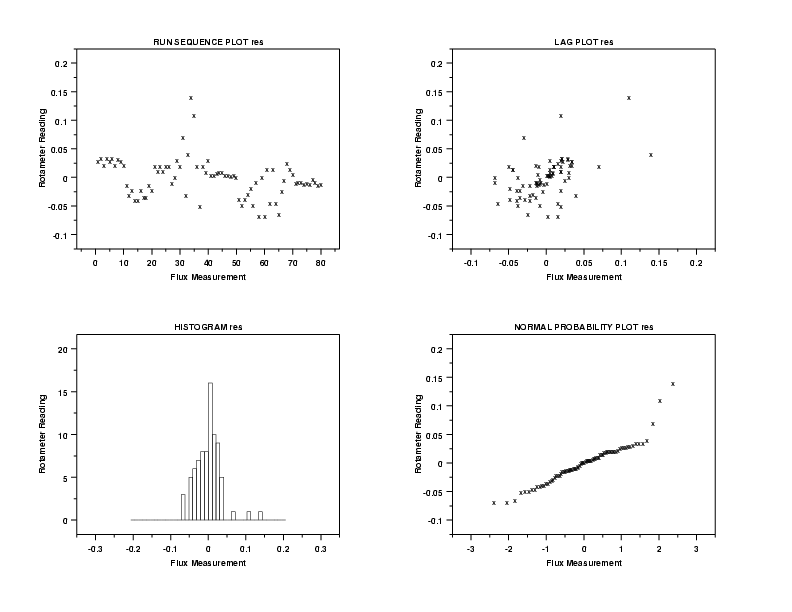
This 4-plot does not show major violations of the regression assumptions. The run sequence plot of the residuals in the upper left corner indicates constant location and scale for the residuals. The lag plot in the upper right corner does not show significant autocorrelation for the residuals. The histogram and normal probability plot indicate that the residuals are reasonably approximated by a normal distribution.
There are several approaches we can take towards addressing the outliers in the residual plots.
- We can accept the quadratic fit as an adequate fit.
- We can use weighting where the weights are proportional to the variance.
- We can use bisquare weighting of the residuals.
- We can delete specific points as outliers.
For this case study, we will use the quadratic model based on deleting two outliers.
