|
|
SORT BY STATISTIC (LET)Name:
In most cases, the sorting statistic will be a location statistic such as the mean, median, minimum, or maximum. However, Dataplot supports 40+ statistics for the sorting statistic. The SORT BY command is a utility command that simplifies the generation of these sorted plots. Specifically, it can be used in conjunction with the following types of plots:
Given a response variable, Y, and a group-id variable, X, the SORT BY command computes the value of a specified statistic for each group and returns the following two variables:
<SUBSET/EXCEPT/FOR qualification> where <y> is the response variable; <x> is the group-id variable; <stat> is one of the following statistics:
GEOMETRIC MEAN, HARMONIC MEAN, HODGES LEHMAN, BIWEIGHT LOCATION, SUM, PRODUCT, SIZE (or NUMBER or SIZE), STANDARD DEVIATION, STANDARD DEVIATION OF MEAN, VARIANCE, VARIANCE OF THE MEAN, TRIMMED MEAN STANDARD ERROR, AVERAGE ABSOLUTE DEVIATION (or AAD), MEDIAN ABSOLUTE DEVIATION (or MAD), IQ RANGE, BIWEIGHT MIDVARIANCE, BIWEIGHT SCALE, PERCENTAGE BEND MIDVARIANCE, WINSORIZED VARIANCE, WINSORIZED STANDARD DEVIATION, RELATIVE STANDARD DEVIATION, RELATIVE VARIANCE, COEFFICIENT OF VARIATION, RANGE, MIDRANGE, MAXIMUM, MINIMUM, EXTREME, LOWER HINGE, UPPER HINGE, LOWER QUARTILE, UPPER QUARTILE, <FIRST/SECOND/THIRD/FOURTH/FIFTH/SIXTH/SEVENTH/EIGHTH/ NINTH/TENTH> DECILE, PERCENTILE, QUANTILE, QUANTILE STANDARD ERROR, SKEWNESS, KURTOSIS, NORMAL PPCC, AUTOCORRELATION, AUTOCOVARIANCE, SIN FREQUENCY, SIN AMPLITUDE, CP, CPK, CNPK, CPM, CC, EXPECTED LOSS, PERCENT DEFECTIVE, TAGUCHI SN0 (or SN), TAGUCHI SN+ (or SNL), TAGUCHI SN- (or SNS), TAGUCHI SN00 (or SN2); <index> is a variable where the ranking of the statistic for each group are stored; and where the <SUBSET/EXCEPT/FOR qualification> is optional.
LET X2 INDX = SORT BY MEIDAN Y X LET X2 INDX = SORT BY SD Y X LET X2 INDX = SORT BY MINIMUM Y X LET X2 INDX = SORT BY IQ RANGE Y X
skip 25
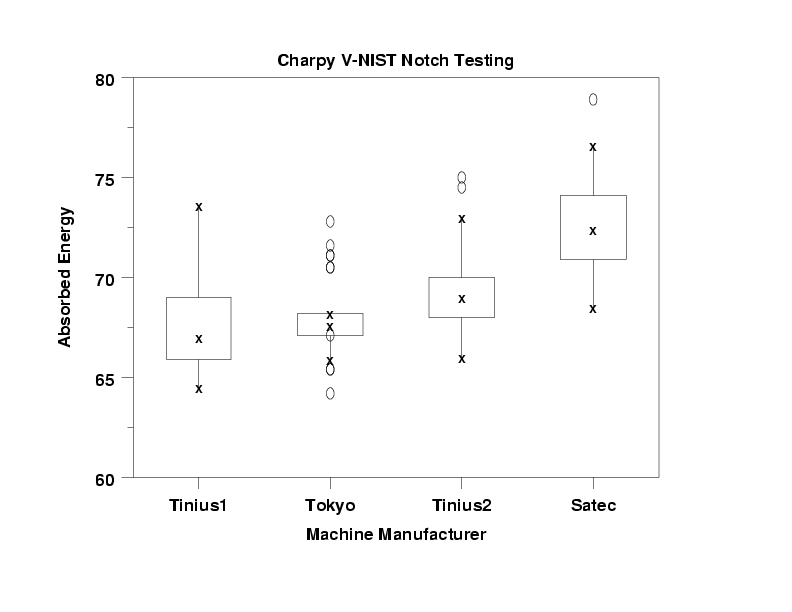
read splett2.dat y x
.
let x2 indx = sort by median y x
let ig = group label Tinius1 Tinius2 Satec Tokyo
x1tic mark label case asis
x1tic mark label format group labels
x1tic mark label content ig indx
.
char box plot
line box plot
fences on
.
xlimits 1 4
major xtic mark number 4
minor xtic mark number 0
xtic offset 0.5 0.5
.
title case asis
title offset 2
title Charpy V-NIST Notch Testing
label case asis
x1label Machine Manufacturer
y1label Absorbed Energy
.
box plot y x2
set convert character on
skip 25
read draft69c.dat rank day month
.
let ig = group label month
x1tic mark label format group label
let xcode = character code month
.
major xtic mark number 12
minor xtic mark number 0
xlimits 1 12
xtic offset 0.5 0.5
.
let xcode2 indx = sort by mean rank xcode
x1tic mark label content ig indx
.
x1tic mark label size 1.5
tic mark label case asis
label case asis
title case asis
title displacement 2
x1label Month
y1label Draft Ranking
title Mean Plot Ordered by Mean
.
mean plot rank xcode2
 Program 3:
Program 3:
skip 25
read splett2.dat y x
.
let ig = group label Tinius1 Tinius2 Satec Tokyo
.
char x blank
line blank dash
.
xlimits 1 4
major xtic mark number 4
minor xtic mark number 0
tic offset units screen
tic offset 5 5
.
title offset 2
multiplot corner coordinates 0 0 100 100
multiplot 2 2
multiplot scale factor 2
.
x1tic mark label format group label
x1tic mark label content ig
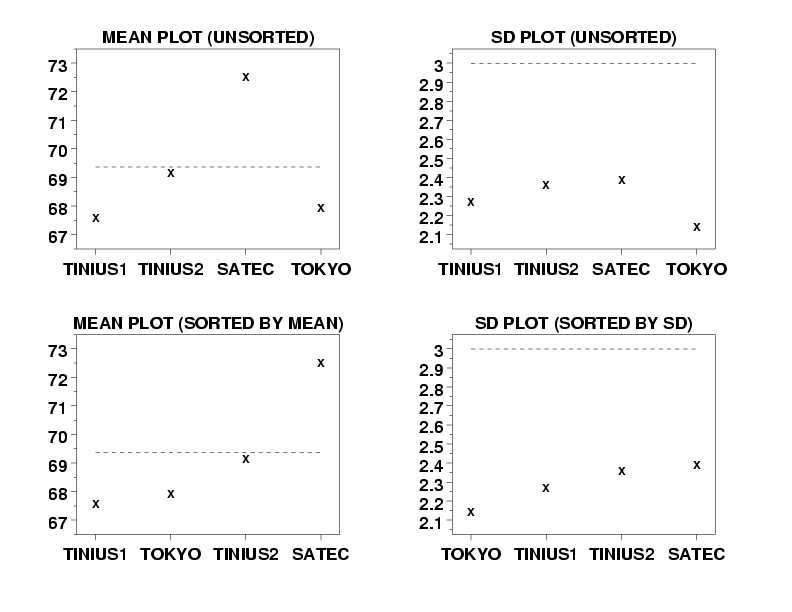
title Mean Plot (Unsorted)
mean plot y x
.
title SD Plot (Unsorted)
sd plot y x
.
title Mean Plot (Sorted by Mean)
let x2 indx = sort by mean y x
x1tic mark label content ig indx
mean plot y x2
.
title SD Plot (Sorted by SD)
let x2 indx = sort by sd y x
x1tic mark label content ig indx
sd plot y x2
.
end of multiplot
 Program 4:
Program 4:
skip 25
read gear.dat y x
.
char x all
line solid all
.
xlimits 1 10
major xtic mark number 10
minor xtic mark number 0
xtic offset 0.5 0.5
.
title offset 2
multiplot corner coordinates 0 0 100 100
multiplot 2 2
multiplot scale factor 2
.
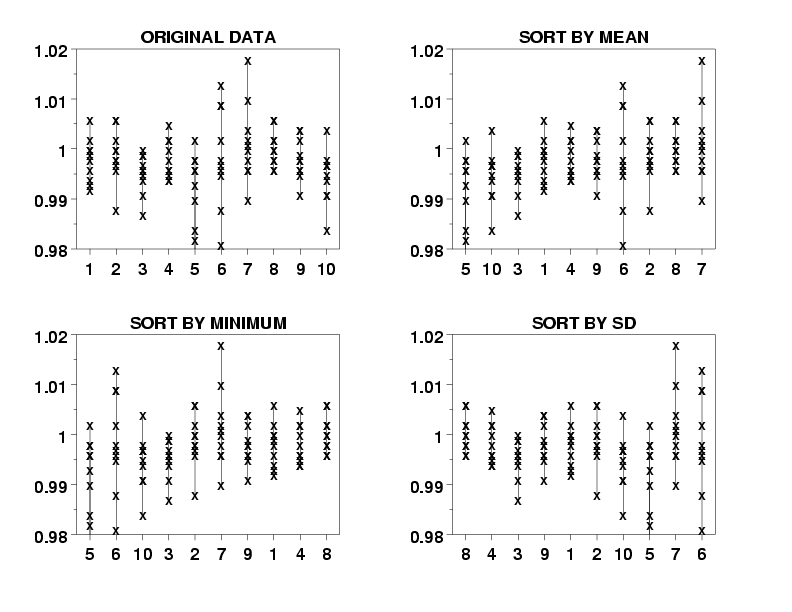
title Original Data
plot y x x
.
title Sort by Mean
let x2 indx = sort by mean y x
x1tic mark label format variable
x1tic mark label content indx
plot y x2 x2
.
title Sort by Minimum
let x2 indx = sort by minimum y x
x1tic mark label content indx
plot y x2 x2
.
title Sort by SD
let x2 indx = sort by sd y x
x1tic mark label content indx
plot y x2 x2
.
end of multiplot
Date created: 1/26/2006 |