8.2. Assumptions/Prerequisites
8.2.2. How do you plot reliability data?
8.2.2.2. |
Hazard and cumulative hazard plotting |
Advantages of Cumulative Hazard Plotting
- It is much easier to calculate plotting positions for multicensored data using cumulative hazard plotting techniques.
- The most common reliability distributions, the exponential and the Weibull, are easily plotted.
- It is less intuitively clear just what is being plotted. In a probability plot, the cumulative percent failed is meaningful and the resulting straight-line fit can be used to identify times when desired percentages of the population will have failed. The percent cumulative hazard can increase beyond 100 % and is harder to interpret.
- Normal cumulative hazard plotting techniques require exact times of failure and running times.
- Since computers are able to calculate K-M estimates for probability plotting, the main advantage of cumulative hazard plotting goes away.
How to Make Cumulative Hazard Plots
- Order the failure times and running times for each of the \(n\) units on test in ascending order from 1 to \(n\) The order is called the rank of the unit. Calculate the reverse rank for each unit (reverse rank = \(n - \mbox{rank} + 1\)).
- Calculate a hazard "value" for every failed unit (do this only for the failed units). The hazard value for the failed unit with reverse rank \(k\) is just \(1/k\).
- Calculate the cumulative hazard values for each failed unit. The cumulative hazard value corresponding to a particular failed unit is the sum of all the hazard values for failed units with ranks up to and including that failed unit.
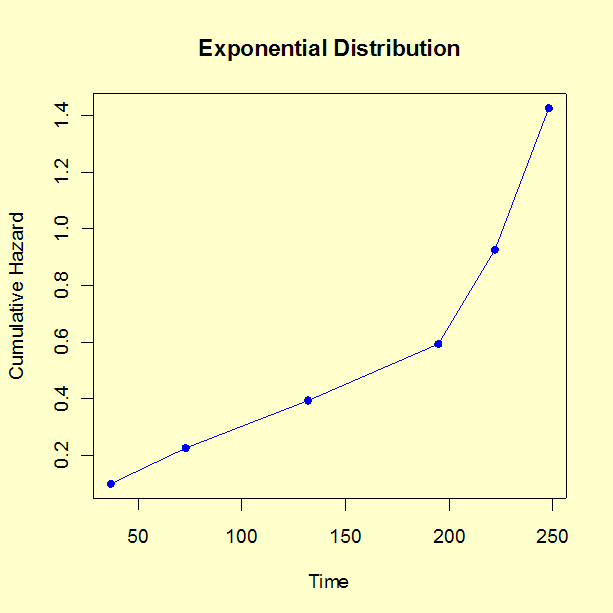
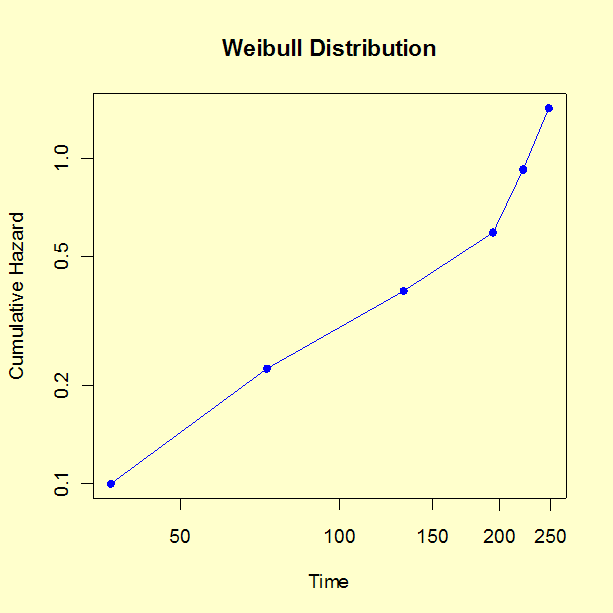
- Plot the time of failure versus the cumulative hazard value. Linear \(x\) and \(y\) scales are appropriate for an exponential distribution, while a log-log scale is appropriate for a Weibull distribution.
|
Time of Event |
1= failure 0=runtime |
Rank |
Reverse Rank |
Haz Val (2) x 1/(4) |
Cum Hazard Value |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Next ignore the rows with no cumulative hazard value and plot column (1) vs column (6).
The cumulative hazard for the exponential distribution is just \(H(t) = \alpha t\), which is linear in \(t\) with an intercept of zero. So a simple linear graph of \(y\) = column (6) versus \(x\) = column (1) should line up as approximately a straight line going through the origin with slope \(\lambda\) if the exponential model is appropriate. The cumulative hazard plot for exponential distribution is shown below.