
|
|
KS PLOTName:
The KS plot modifies the ppcc plot by using the value of the Kolmogorov-Smirnov goodness of fit statistic as the measure of distributional fit rather than the correlation coefficient of the probability plot. For the KS plot, we are looking for the value of the shape parameter that minimizes the Kolmogorov-Smirnov statistic. The KS plot is formed by selecting a value of the shape parameter and computing the value of the Kolmogorov-Smirnov goodness of fit test. The KS plot then consists of:
The value of the distributional parameter (on the horizontal axis) which corresponds to the minimum of the KS plot curve (on the vertical axis) indicates the best-fit member of the family. One complication of the KS plot is that it is not invariant to the choice of location and scale parameters. There are two possible solutions to this.
The KS plot can be used with distributions that have two shape parameters. Dataplot supports two formats for the KS plot with two shape parameters:
You can specify which format to use with the command
KS plots are available for the following continuous distributional families (with the distributional parameter in parentheses) with one shape parameter:
KS plots are available for the following continuous distributional families (with the distributional parameter in parentheses) with two shape parameters:
Note that if the two shape parameter case is drawn as multiple traces on a 2d plot, the value of the second shape parameter listed is represented by x axis while each curve represents a different value of the first shape parameter listed above). KS plots are available for the following discrete distributional families (with the distributional parameter in parentheses):
Note that the Kolmogorov-Smirnov goodness of fit test is undefined for discrete distribution. So for discrete distributions, the chi-square goodness of fit statistic is used. At this point we have done limited testing of the KS plot relative to the ppcc plot. However, some preliminary simulations suggest the following:
In summary, either the ppcc plot and ks plot should work well for continuous distributions with a single shape parameter. However, for continuous distributions with two shape parameters or for discrete distributions, the ks plot may provide better fits.
where <x> is the variable of raw data values under analysis; <family> is one of the distributions listed above:
DOUBLE WEIBULL INVERTED WEIBULL GAMMA DOUBLE GAMMA LOG GAMMA INVERTED GAMMA WALD FATIGUE LIFE PARETO PARETO SECOND KIND FRECHET (for extreme value type 2) GENERALIZED EXTREME VALUE GEOMETRIC EXTREME EXPONENTIAL TUKEY LAMBDA SKEW NORMAL T FOLDED T CHI-SQUARE CHI GENERALIZED LOGISTIC LOG DOUBLE EXPONENTIAL ERROR LOGNORMAL POWER NORMAL VON MISES RECIPROCAL LOG LOGISTIC INVERSE GAUSSIAN RECIPROCAL INVERSE GAUSSIAN GENERALIZED GAMMA EXPONENTIATED WEIBULL EXPONENTIAL POWER BETA TWO SIDED POWER JOHNSON SU JOHNSON SB ALPHA GOMPERTZ G AND H F LOG SKEW NORMAL POWER LOGNORMAL FOLDED NORMAL FOLDED CAUCHY SKEW T NONCENTRAL T GEOMTRIC YULE POISSON LOGARITHMIC SERIES HERMITE BETA BINOMIAL NEGATIVE BINOMIAL WARING and where the This syntax is used for the case where have raw data.
where <y> is the variable of pre-computed frequencies; <x> is the variable of distinct values for the variable under analysis; <family> is one of the families listed above; and where the This syntax is used for the case where we have frequency data. Note: Currently, the KS plot for the case of two shape parameters or discrete distributions is not implemented for the case where the data is given in frequency format.
T KS PLOT X EXTREME VALUE TYPE 2 KS PLOT X POISSON KS PLOT X LAMBDA KS PLOT F X
Some disadvantages of these methods are:
LET GAMMA1 = 0.5 LET GAMMA2 = 20 WEIBULL KS PLOT Y A common use of this is to obtain a refinement of the estimate of the shape parameter. That is, an initial iteration (typically just the default values of the parameter) is used to identify the appropriate neighborhood of the optimal value of the shape parameter. Then a second iteration of the KS PLOT is generated with the parameter restricted to a much narrower range of values. Although this iteration can be repeated as many times as you like, for practical purposes a two iterations is typically sufficient.
In the case of two shape parameters, these are saved as SHAPE1 and SHAPE2.
before generating the ppcc plot. For the noncentral t and noncentral chi-square distributions, we can fix the value of the degrees of freedom parameter to a single value. In this case, the ppcc plot reverts to a one shape parameter plot. Enter the commands
LET NU2 = <value>
where
FRECHET and EV2 are synonyms for EXTREME VALUE TYPE 2. LAMBDA KS PLOT and TUKEY KS PLOT are synonyms for TUKEY LAMBDA KS PLOT. STUDENT T KS PLOT is a synonym for T KS PLOT. The CHISQUARE term can be specified as CHISQUARE or CHI SQUARE. FL KS PLOT, BRIN SAUNDERS KS PLOT, and SAUNDERS BRIN are synonyms for FATIGUE LIFE KS PLOT. IG KS PLOT is a synonym for INVERSE GAUSSIAN KS PLOT. RIG KS PLOT is a synonym for RECIPROCAL INVERSE GAUSSIAN PPCC PLOT. GEP KS PLOT and GP KS PLOT are synonyums for GENERALIZED PARETO PLOT. LOGNORMAL KS PLOT and LOG-NORMAL KS PLOT are synonyms for LOG NORMAL KS PLOT. POWER LOG-NORMAL KS PLOT and POWER LOGNORMAL KS PLOT are synonyms for POWER LOG NORMAL KS PLOT. VONMISES KS PLOT and VON-MISES KS PLOT are synonyms for VON MISES KS PLOT. LOGLOGISTIC KS PLOT and LOG-LOGISTIC KS PLOT are synonyms for LOG LOGISTIC KS PLOT.
Conover (1999), "Practical Nonparametric Statistics," Third Edition, Wiley, chapter 6.
LET NU = 10
LET LAMBDA = 1.4
LET Y = NONCENTRAL T RAND NUMBERS FOR I = 1 1 100
.
CASE ASIS
LABEL CASE ASIS
TITLE CASE ASIS
X1LABEL DISPLACEMENT 6
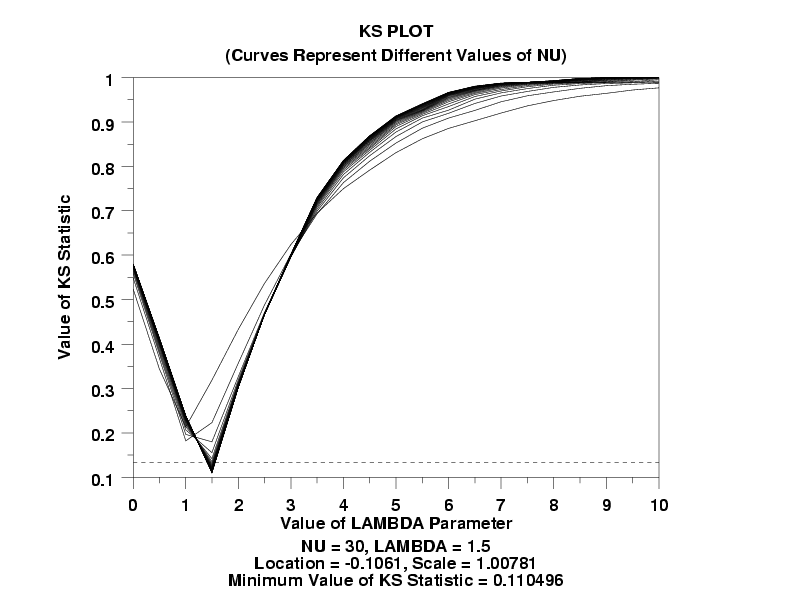
TITLE KS PLOTCR()(Curves Represent Different Values of NU)
Y1LABEL Value of KS Statistic
X1LABEL Value of LAMBDA Parameter
NONCENTRAL T KS PLOT Y
.
LINE DASH
DRAWDATA 0 0.134 10 0.134
JUSTIFICATION CENTER
MOVE 50 7
TEXT NU = ^SHAPE1, LAMBDA = ^SHAPE2
MOVE 50 4
TEXT Location = ^KSLOCS, Scale = ^KSSCALES
MOVE 50 1
TEXT Minimum Value of KS Statistic = ^MINKS
Program 2:
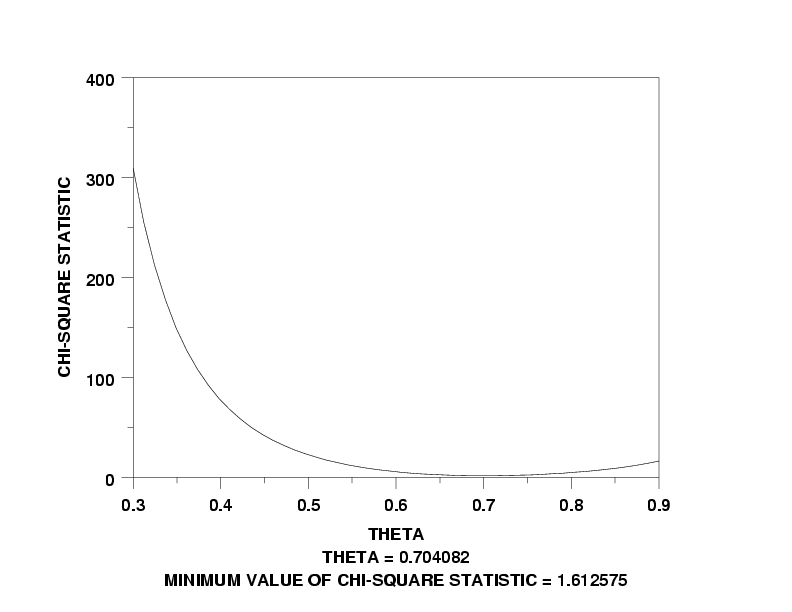
LET THETA = 0.7
LET Y = LOGARITHMIC SERIES RAND NUMBERS FOR I = 1 1 100
LET THETA1 = 0.3
LET THETA2 = 0.9
X1LABEL THETA
Y1LABEL CHI-SQUARE STATISTIC
LOGARITHMIC SERIES KS PLOT Y
JUSTIFICATION CENTER
MOVE 50 5
TEXT THETA = ^SHAPE
MOVE 50 1
TEXT Minimum Value of Chi-Square Statistic = ^MINKS
|
Privacy
Policy/Security Notice
NIST is an agency of the U.S.
Commerce Department.
Date created: 05/24/2004 | ||||||||||||||||||||||