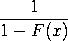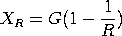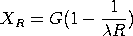Extreme Wind Speeds: Software
|
|
Computational Issues
|
When analyzing a univariate set of data consisting of extreme
winds, the following tasks typically need to be performed.
Later on this page, we discuss software
that can be used to perform some of these tasks.
|
|
Graph the Data
|
Some useful initial graphs of the data are:
- A
run sequence plot of the data is useful for
showing time dependent patterns in the data.
For extreme value analysis, it can be helpful
to draw reference lines at certain threshold
values.
- Graphs showing the distributional shape can
be useful. The most common types of
distributional graphs are
histograms and kernel density plots.
|
|
Determine an Appropriate Distribution
|
For extreme values, the following are the most commonly
used distributions:
|
|
Estimate the Parameters of the Distribution
|
There are a number of methods for estimating the parameters
of a distribution. These include:
Maximum likelihood procedures are well developed for
Gumbel, Frechet, and Weibull distributions. Maximum
likelihood for the generalized Pareto distribution is
problematic in that the maximum likelihood solution does
not exist for certain domains of the shape parameter.
The PPCC/probability plot method works well for the five
extreme value distributions considered here. For the Frechet
distribution, using the
Kolmogorov-Smirnov plot may improve upon the PPCC plot.
One issue in developing distributional models for
extreme winds data is that we typically want a
distributional model for the extreme points (i.e., the
points above a given threshold) of the data rather
than the full data set.
|
|
Assess Goodness of Fit
|
Once a candidate model has been fit, the next to step is
to assess the goodness of fit of that model. Some methods
for doing this are:
|
|
Using the Fitted Model
|
Once an adequate distributional model has been found, this
model will typically be used to estimate some quantities of
of interest. For example,
- Estimate specific quantiles of the distribution
Quantiles are estimated from the
percent point function (also known as the
inverse cumulative distribution function).
- Estimate return intervals and wind speeds corresponding
to a given return interval
The return interval (or mean recurrence interval) of a
given wind speed, in years, is defined as the inverse
of the probability that the wind speed will be exceeded
in any one year. It is defined as
with F(x) denoting the cumulative
distribution function.
More often, we would like to compute the wind speed
that corresponds to a given mean return interval. The
solution to this is given by solving the above
equation for x
with G and R denoting the percent point function
and the desired mean recurrence interval, respectively.
The above formula is for the case of a set consisting of
single yearly maxima. If
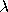 is mean number of threshold crossings of the extreme
speed record per year, the formula is
is mean number of threshold crossings of the extreme
speed record per year, the formula is
See Simiu and
Scanlan for a more complete discussion of mean
recurrence intervals.
|
|
Software for Extreme Wind Speeds
|
We discuss how some of these computational issues can be
addressed in a few different software environments. We also
provide several Fortran-based codes that can be used to
analyze some of the data sets provided on this web site.
- Fortran-based Program for
Analyzing Hurricane Wind Speeds
- Fortran-based Program for
Analyzing Daily Maximums
- Dataplot
- e-FITS
web site (currently restricted to NIST staff)
- Excel-based procedures
- ASOS data
Software is provided for extracting wind speed data
from ASOS data sets. The software has the capability
of extracting separately non-thunderstorm and
thunderstorm wind speeds.
Note that the above list is not exhaustive. Many commercial
statistical/mathematical programs can be used to analyze
extreme value data. The software described above is intended
to provide an example of how these analyses can be performed
and is not meant to imply that these software programs are
recommended for this task.
|
|
[ SED Home |
Extreme Winds Home |
Previous |
Next ]
Privacy
Policy/Security Notice
Disclaimer |
FOIA
NIST is an agency of the U.S.
Commerce Department.
Date created: 03/05/2004
Last updated: 10/03/2016
Please email comments on this WWW page to
SED_webmaster@nist.gov
|