
|
|
HISTOGRAMName:
There are 4 types of histograms:
The histogram and the frequency plot have the same information except the histogram has bars at the frequency values, whereas the frequency plot has lines connecting the frequency values.
where <type> is one of HISTOGRAM, RELATIVE HISTOGRAM, CUMULATIVE HISTOGRAM, or CUMULATIVE RELATIVE HISTOGRAM; <x> is a variable of raw data values; and where the <SUBSET/EXCEPT/FOR qualification is optional. This syntax is used when you have raw data. Note that <x> can be either a variable or a matrix. If <x> is a matrix, then a histogram will be generated for all values in that matrix.
where <type> is one of HISTOGRAM, RELATIVE HISTOGRAM, CUMULATIVE HISTOGRAM, or CUMULATIVE RELATIVE HISTOGRAM; <y> is a variable containing pre-computed frequencies; <x> is a variable containing the bin mid-points; and where the <SUBSET/EXCEPT/FOR qualification is optional. This syntax is used when you have grouped data with equi-sized bins.
where <type> is one of HISTOGRAM, RELATIVE HISTOGRAM, CUMULATIVE HISTOGRAM, or CUMULATIVE RELATIVE HISTOGRAM; <y> is a variable containing pre-computed frequencies; <xlow> is a variable containing the lower limits for the bins; <xhigh> is a variable containing the upper limits for the bins; and where the <SUBSET/EXCEPT/FOR qualification is optional. This syntax is used when you have grouped data with unequal sized bins.
where <type> is one of HISTOGRAM, RELATIVE HISTOGRAM, CUMULATIVE HISTOGRAM, or CUMULATIVE RELATIVE HISTOGRAM; <y> is a variable of raw data values; <x> is a group-id variable; and where the <SUBSET/EXCEPT/FOR qualification is optional. This syntax can be used to highlight the contribution to the histogram for particular subsets of the data. It is demonstrated in the program examples below.
RELATIVE HISTOGRAM TEMP CUMULATIVE HISTOGRAM TEMP CUMULATIVE RELATIVE HISTOGRAM TEMP HISTOGRAM COUNTS STATE RELATIVE HISTOGRAM COUNTS STATE CUMULATIVE HISTOGRAM COUNTS STATE CUMULATIVE RELATIVE HISTOGRAM COUNTS STATE
The first method simply divides the count in the bin by the total count. That is, the relative frequency of the i-th bin is \( n_{i}/\sum{n_{i}} \) where \( n_{i} \) is the count of the i-th bin. In this case, the sum of the relative frequencies is one. To specify this method, enter the command
The second method normalizes the counts so that the area sums to one. That is, the relative frequency of the i-th bin is \( n_{i}/\sum{n_{i} c_{i}} \) where \( c_{i} \) is the width of the i-th bin. To specify this method, enter the command
The advantage of the AREA method is that it makes the relative histogram an estimator of the underlying probability distribution. The histogram in this case is actually a simple kernel density estimator of the underlying distribution of the data. This is not the case when the PERCENT option is used. The default is AREA.
LET YFREQ = YPLOT LET XVAL = XPLOT Then the variables YFREQ and XVAL contain a frequency table. You can also use the
command for this purpose.
A number of alternative choices for class width can be set with the command
Enter HELP HISTOGRAM CLASS WIDTH for details.
To revert to the default, enter
To restore the default, enter
with XLOW containing the values for the lower bin limit and XHIGH containing the values for the upper bin limit.
In this case, X is a group-id variable. This syntax can be used to highlight the contribution to the histogram for particular subsets of the data.
When you have data where there are a small percentage of points that are quite far from the bulk of the data, you might want to use the command (this already existed, enter HELP HISTOGRAM CLASS WIDTH for details).
This bases the bin width for the histogram on the interquartile range rather than the standard deviation as the other class width algorithms do. This can result in more reasonable class widths for the center of the data when there are extreme outliers in the data. Also, these commands are typically used when the
command is also given (this command extends the bins to cover all outliers).
David Scott (1992), "Multivariate Density Estimation", John Wiley, (chapter 3). This book discusses histograms as "density estimators" and gives optimal criterion for selecting the class width.
2004/09: Support alternative class width algorithms 2007/03: Option to compute histogram of a matrix 2010/01: Support for HIGHLIGHT/SUBSET option 2010/01: Support for non-equispaced histograms 2010/01: Option to suppress empty bins 2010/01: Option to include outliers 2016/06: Support for SET HISTOGRAM MAXIMUM CLASSES 2016/06: Support for SET HISTOGRAM OUTLIER POINTS
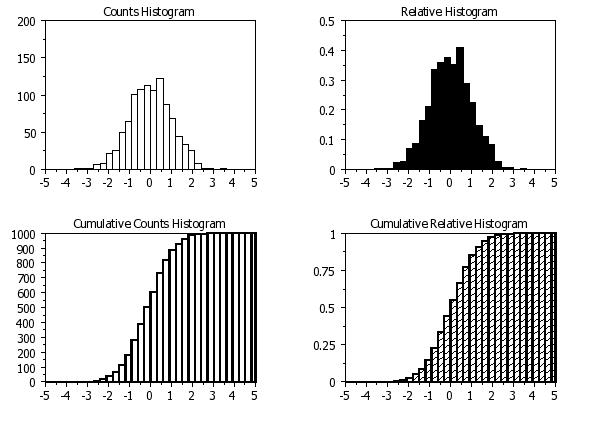
LET Y = NORMAL RANDOM NUMBERS FOR I = 1 1 1000
MULTIPLOT 2 2
MULTIPLOT SCALE FACTOR 2
MULTIPLOT CORNER COORDINATES 0 0 100 100
XLIMITS -5 5
TITLE CASE ASIS
TITLE OFFSET 2
TITLE Counts Histogram
HISTOGRAM Y
BAR FILL ON
TITLE Relative Histogram
RELATIVE HISTOGRAM Y
BAR FILL OFF
BAR BORDER THICKNESS 0.3
TITLE Cumulative Counts Histogram
CUMULATIVE HISTOGRAM Y
BAR FILL ON
BAR PATTERN D1
BAR PATTERN SPACING 3
TITLE Cumulative Relative Histogram
CUMULATIVE RELATIVE HISTOGRAM Y
END OF MULTIPLOT
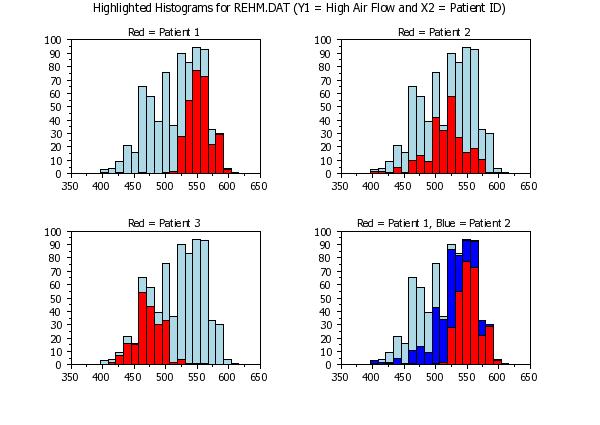
 Program 2:
Program 2:
. Demonstrate the SUBSET option
skip 25
read rehm.dat y1 y2 x1 x2
.
bar on on on
bar fill on on on
bar fill color lblue red
line blank blank
xlimits 350 650
.
multiplot 2 2
let tag = x2
let tag = 1 subset x2 = 1
let tag = 2 subset x2 <> 1
title Red = Patient 1
highlighted hist y1 tag
let tag = 1 subset x2 = 2
let tag = 2 subset x2 <> 2
title Red = Patient 2
highlighted hist y1 tag
let tag = 1 subset x2 = 3
let tag = 2 subset x2 <> 3
title Red = Patient 3
highlighted hist y1 tag
bar fill color lblu blue red
title Red = Patient 1, Blue = Patient 2
highlighted hist y1 x2
end of multiplot
.
xlimits
move 50 97
just center
case asis
text Highlighted Histograms for REHM.DAT (Y1 = High Air Flow and X2 = Patient ID)
Date created: 11/30/2010 |
Last updated: 12/04/2023 Please email comments on this WWW page to [email protected]. | ||||||||||||||||||||||||||||||||||||||||||||||