
|
|
REGRESSION DIAGNOSTICSName:
The above are demonstrated in the Program example below. Note that this program example is meant to show the mechanics of the various plots and commands and is not intended to be treated as a case study. One purpose of many regression diagnostics is to identify observations with either high leverage or high influence. High leverage points are those that are outliers with respect to the independent variables. Influential points are those that cause large changes in the parameter estimates when they are deleted. Although an influential point will typically have high leverage, a high leverage point is not necessarily an influential point. The leverage is typically defined as the diagonal of the hat matrix (hat matrix = H = X(X'X)**(-1)X'). Dataplot currently writes a number of measures of influence and leverage to the file dpst3f.dat (e.g., the diagonal of the hat matrix, Cook's distance, DFFITS).
At a minimum, the following diagnostics should be generated
The term "regression diagnostics" is typically used to denote diagnostic statistics and plots that go beyond the standard residual analysis. This is a brief discussion of "regression diagnostics" with respect to linear fits performed with a non-iterative algorithm. Regression diagnostics are used to identify outliers in the dependent variable, identify influential points, to identify high leverage points, or in general to uncover features of the data that could cause difficulties for the fitted regression model. The books by Belsley, Kuh, and Welsch and by Cook and Weisberg listed in the References section discuss regression diagnostics in detail. The mathematical derivations for the diagnostics covered here can be found in these books. Chapter 11 of the Neter, Wasserman, and Kuntner book listed in the References section discusses regression diagnostics in a less theoretical way. We will only give a brief overview of the various regression diagnostics. For more thorough guidance on when these various diagnostics are appropriate and how to interpret them, see one of these texts (or some other text on regression that covers these topics). At a minimum, diagnostic analysis of a linear fit includes the various plots of the residuals and predicted values described above. For more complete diagnostics, the variables written to the file dpst3f.dat can be analyzed. Specifically, this file contains
Additional diagnostic statistics can be computed from these values. Several of the texts in the REFERENCE section below discuss the use and interpretation of these statistics in more detail. These variables can be read in as follows:
SET READ FORMAT 8E15.7 READ DPST3F.DAT HII VARRES STDRES ISTUDRES DELRES ... ESTUDRES COOK DFFITS SKIP 0 Many analysts prefer to use the standardized residuals or the internally studentized residuals for the basic residual analysis. Deleted residuals and externally deleted residuals are used to identify outlying Y observations that the normal residuals do not identify (cases with high leverage tend to generate small residuals even if they are outliers). Many regression diagnostics depend on the Hat matrix \( (X(X'X)^{-1}X' \)). Dataplot has limits on the maximum number of columns/rows for a matrix which may prohibit the creation of the full hat matrix for some problems. Fortunately, most of the relevant statistics can be derived from the diagonal elements of this matrix (which can be read from the dpst3f.dat file). These are also referred to as the leverage points. The minimum leverage is \( (1/n) \), the maximum leverage is 1.0, and the average leverage is \( (p/n) \) where \( p \) is the number of variables in the fit. As a rule of thumb, leverage points greater than twice the average leverage can be considered high leverage. High leverage points are outliers in terms of the \( X \) matrix and have an unduly large influence on the predicted values. High leverage points also tend to have small residuals, so they are not typically detected by standard residual analysis. The DFFITS values are a measure of influence that observation i has on the i-th predicted value. As a rule of thumb, for small or moderate size data sets, values greater than 1 indicate an influential case. For large data sets, values greater than \( 2 \sqrt{p/n} \) indicate influential cases. Cook’s distance is a measure of the combined impact of the i-th observation on all of the regression coefficients. It is typically compared to the F distribution. Values near or above the 50-th percentile imply that observation has substantial influence on the regression parameters. The DFFITS values and the Cook’s distance are used to identify high leverage points that are also influential (in the sense that they have a large effect on the fitted model). Once these variables have been read in, they can be printed, plotted, and used in further calculations like any other variable. This is demonstrated in the program example below. They can also be used to derive additional diagnostic statistics. For example, the program example shows how to compute the Mahalanobis distance and Cook’s V statistic. The Mahalanobis distance is a measure of the distance of an observation from the “center” of the observations and is essentially an alternate measure of leverage. The Cook’s V statistic is the ratio of the variances of the predicted values and the variances of the residuals. Another popular diagnostic is the DFBETA statistic. This is similar to Cook’s distance in that it tries to identify points that have a large influence on the estimated regression coefficients. The distinction is that DFBETA assesses the influence on each individual parameter rather than the parameters as a whole. The DFBETA statistics require the catcher matrix, which is described in the multi-collinearity section below, for easy computation. The usual recommendation for DFBETA is that absolute values larger than 1 for small and medium size data sets and larger than \( 2/\sqrt{N} \) for large data sets should be considered influential. The variables written to file dpst3f.dat are calculated without computing any additional regressions. The statistics based on a case being deleted are computed from mathematically equivalent formulas that do not require additional regressions to be performed. The Neter, Wasserman, and Kunter text gives the formulas that are actually used. Robust regression is often recommended when there are significant outliers in the data. One common robust technique is called iteratively reweighted least squares (IRLS) (or M-estimation). Note that these techniques protect against outlying Y values, but they do not protect against outliers in the X matrix. Also, they test for single outliers and are not as sensitive for a group of similar outliers. See the documentation for WEIGHTS, BIWEIGHT, and TRICUBE for more information on performing IRLS regression in DATAPLOT. Techniques for protecting against outliers in the X matrix use alternatives to least squares. Two such methods are least median squares regression (also called LSQ regression) and least trimmed squares regression (also called LTS regression). Dataplot does not support these techniques at this time. The documentation for the WEIGHTS command in the Support chapter discusses one approach for dealing with outliers in the X matrix in the context of IRLS.
The VIF values are often given as their reciprocals (this is called the tolerance). Fortunately, these values can be computed without performing any additional regressions. The computing formulas are based on the catcher matrix, which is \( X(X'X)^{-1} \). The equation is:
where c is the catcher matrix. Another measure of multi-collinearity are the condition indices. The condition indices are calculated as follows:
Belsley, Kuh, and Welsch, (1980), "Regression Diagnostics", John Wiley. Neter, Wasserman, and Kunter (1990), "Applied Linear Statistical Models", 3rd ed., Irwin.
. Note: this program example is meant simply to show how to create
. the various plots, intervals and statistics. It is not a
. case study.
.
. ZARTHAN COMPAY EXAMPLE FROM
. "APPLIED LINEAR STATISTICAL MODELS", BY NETER, WASSERMAN, KUTNER
.
. Y = SALES
. X1 = CONSTANT TERM
. X2 = TARGET POPULATION (IN THOUSANDS)
. X3 = PER CAPITA DISCRETIONARY INCOME (DOLLARS)
.
. Step 1: Read the data
.
DIMENSION 500 COLUMNS
LET NVAR = 2
READ DISTRICT Y X2 X3
1 162 274 2450
2 120 180 3254
3 223 375 3802
4 131 205 2838
5 67 86 2347
6 169 265 3782
7 81 98 3008
8 192 330 2450
9 116 195 2137
10 55 53 2560
11 252 430 4020
12 232 372 4427
13 144 236 2660
14 103 157 2088
15 212 370 2605
END OF DATA
.
LET N = SIZE Y
LET X1 = 1 FOR I = 1 1 N
LET STRING SY = Sales
LET STRING SX2 = Population
LET STRING SX3 = Income
LET P = NVAR + 1
.
. Step 1: Basic Preliminary Plots
. 1) Independent against dependent
. 2) INDEPENDENT AGAINST INDEPENDENT
.
TITLE OFFSET 2
TITLE AUTOMATIC
TITLE CASE ASIS
LABEL CASE ASIS
CASE ASIS
.
LINE BLANK
CHARACTER CIRCLE
CHARACTER HW 1 0.75
CHARACTER FILL ON
Y1LABEL DISPLACEMENT 12
X1LABEL DISPLACEMENT 10
X2LABEL DISPLACEMENT 15
.
MULTIPLOT CORNER COORDINATES 5 5 95 95
MULTIPLOT SCALE FACTOR 2
MULTIPLOT 2 2
.
Y1LABEL ^SY
LOOP FOR K = 2 1 P
LET RIJ = CORRELATION Y X^K
LET RIJ = ROUND(RIJ,3)
X1LABEL ^SX^K
X2LABEL Correlation: ^RIJ
PLOT Y VS X^K
END OF LOOP
.
LOOP FOR K = 2 1 P
LET IK1 = K + 1
Y1LABEL ^SX^K
LOOP FOR J = IK1 1 P
LET RIJ = CORRELATION X^K X^J
LET RIJ = ROUND(RIJ,3)
X1LABEL ^SX^J
X2LABEL Correlation: ^RIJ
PLOT X^K VS X^J
END OF LOOP
END OF LOOP
END OF MULTIPLOT
LABEL
.
JUSTIFICATION CENTER
MOVE 50 97
TEXT Basic Preliminary Plots
.
. Step 2: Generate the fit
.
SET WRITE DECIMALS 5
SET LIST NEW WINDOW OFF
FEEDBACK OFF
capture program3.out
FIT Y X2 X3
WRITE " "
WRITE " "
WRITE " "
WRITE " ANOVA Table"
WRITE " "
LIST dpst5f.dat
WRITE " "
WRITE " "
CAPTURE SUSPEND
.
. Step 3b: Generate the basic residual analysis
.
TITLE SIZE 4
TIC MARK LABEL SIZE 4
CHARACTER HW 2 1.5
SET 4PLOT MULTIPLOT ON
TITLE AUTOMATIC
4-PLOT RES
TITLE SIZE 2
TIC MARK LABEL SIZE 2
CHARACTER HW 1 0.75
.
MULTIPLOT 2 2
TITLE AUTOMATIC
Y1LABEL Predicted Values
X1LABEL Response Values
PLOT PRED VS Y
Y1LABEL Residuals
X1LABEL Predicted Values
PLOT RES VS PRED
LOOP FOR K = 2 1 P
Y1LABEL Residuals
X1LABEL Predicted Values
PLOT RES VS X^K
END OF LOOP
END OF MULTIPLOT
LABEL
TITLE
.
. Step 3c: Read the information written to auxiliary files. Some of
. these values will be used later in this macro.
.
SKIP 1
READ dpst1f.dat COEF COEFSD TVALUE PARBONLL PARBONUL
READ dpst2f.dat PREDSD PRED95LL PRED95UL PREDBLL PREDBUL PREDHLL PREDHUL
READ dpst3f.dat HII VARRES STDRES STUDRES DELRES ESTUDRES COOK DFFITS
READ dpst4f.dat TEMP1 TEMP2
LET S2B = VARIABLE TO MATRIX TEMP1 P
LET XTXINV = VARIABLE TO MATRIX TEMP2 P
DELETE TEMP1 TEMP2
SKIP 0
.
. Step 4: Partial Residual and Partial Regression Plots, CCPR and
. Partial Leverage Plots not generated
.
MULTIPLOT 2 2
TITLE AUTOMATIC
Y1LABEL Residuals + A1*X2
X1LABEL X2
PARTIAL RESIDUAL PLOT Y X2 X3 X2
Y1LABEL Residuals + A2*X3
X1LABEL X3
PARTIAL RESIDUAL PLOT Y X2 X3 X3
.
Y1LABEL Residuals: X2 Removed
X1LABEL Residuals: X2 Versus X3
PARTIAL REGRESSION PLOT Y X2 X3 X2
Y1LABEL Residuals: X3 Removed
X1LABEL Residuals: X3 Versus X2
PARTIAL REGRESSION PLOT Y X2 X3 X3
END OF MULTIPLOT
TITLE
LABEL
JUSTIFICATION CENTER
MOVE 50 97
Text Partial Residual and Partial Regression Plots
.
. Step 5: Calculate function to calculate regression estimate
. for new data (F)
.
LET A0 = COEF(1)
LET FUNCTION F = A0
LET DUMMY = PREDSD(1)
.
. Use (2*NVAR) rather than (2*P) if no constant term in
. joint interval
.
LOOP FOR K = 1 1 NVAR
LET INDX = K + 1
LET A^K = COEF(INDX)
LET FUNCTION F = F + (A^K)*(Z^K)
END OF LOOP
.
LET Z1 = DATA 220 375
LET Z2 = DATA 2500 3500
LET YNEW = F
.
CAPTURE RESUME
PRINT " "
PRINT " "
PRINT "NEW X VALUES, ESTIMATED NEW VALUE"
PRINT Z1 Z2 YNEW
CAPTURE SUSPEND
.
. Step 5b: Print the X'X inverse matrix and parameter
. variance-covariance matrix
.
CAPTURE RESUME
PRINT " "
PRINT " "
PRINT "THE X'X INVERSE MATRIX"
PRINT XTXINV
.
PRINT " "
PRINT " "
PRINT "THE PARAMETER VARIANCE-COVARIANCE MATRIX"
PRINT S2B
CAPTURE SUSPEND
.
. Step 5c: Calculate:
. 1) The variance of a new point (S2YHAT)
. 2) A confidence interval for a new point
. 3) A joint confidence interval for more than one point
. 4) A prediction interval for a new point
. 5) A Scheffe joint prediction interval for more than one point
.
LET NPT = SIZE YNEW
LET NP = N - P
LOOP FOR IK = 1 1 NPT
LET XNEW(1) = 1
LET XNEW(2) = Z1(IK)
LET XNEW(3) = Z2(IK)
LOOP FOR K = 1 1 P
LET DUMMY2 = VECTOR DOT PRODUCT XNEW S2B^K
LET SUMZ(K) = DUMMY2
END OF LOOP
LET S2YHAT = VECTOR DOT PRODUCT SUMZ XNEW
LET S2YPRED = MSE + S2YHAT
LET YHATS2(IK) = S2YHAT
LET YPREDS2(IK) = S2YPRED
LET SYHAT = SQRT(S2YHAT)
LET YHATS(IK) = SYHAT
LET SYPRED = SQRT(S2YPRED)
LET YPREDS(IK) = SYPRED
LET YHAT = YNEW(IK)
CAPTURE RESUME
PRINT " "
PRINT " "
PRINT "THE PREDICTED VALUE FOR THE NEW POINT = ^YHAT"
PRINT "THE VARIANCE OF THE NEW VALUE = ^S2YHAT"
PRINT "THE VARIANCE FOR PREDICTION INTERVALS = ^S2YPRED"
CAPTURE SUSPEND
LET T = TPPF(.975,NP)
LET YHATU = YHAT + T*SYHAT
LET YHATL = YHAT - T*SYHAT
LET YPREDU = YHAT + T*SYPRED
LET YPREDL = YHAT - T*SYPRED
CAPTURE RESUME
PRINT " "
PRINT "95% CONFIDENCE INTERVAL FOR YHAT: ^YHATL <= YHAT <= ^YHATU"
PRINT "95% PREDICTION INTERVAL FOR YHAT: ^YPREDL <= YHAT <= ^YPREDU"
CAPTURE SUSPEND
END OF LOOP
.
LET ALPHA = 0.10
LET DUMMY = 1 - ALPHA/(2*NPT)
LET B = TPPF(DUMMY,NP)
LET JOINTBU = YNEW + B*YHATS
LET JOINTBL = YNEW - B*YHATS
CAPTURE RESUME
PRINT " "
PRINT "90% BONFERRONI JOINT CONFIDENCE INTERVALS FOR NEW VALUES"
PRINT JOINTBL YNEW JOINTBU
CAPTURE SUSPEND
LET W = P*FPPF(.90,P,NP)
LET W = SQRT(W)
LET JOINTWU = YNEW + W*YHATS
LET JOINTWL = YNEW - W*YHATS
CAPTURE RESUME
PRINT " "
PRINT "90% HOTELLING JOINT CONFIDENCE INTERVALS FOR NEW VALUES"
PRINT JOINTWL YNEW JOINTWU
CAPTURE SUSPEND
LET JOINTBU = YNEW + B*YPREDS
LET JOINTBL = YNEW - B*YPREDS
CAPTURE RESUME
PRINT " "
PRINT "90% BONFERRONI JOINT PREDICTION INTERVALS FOR NEW VALUES"
PRINT JOINTBL YNEW JOINTBU
CAPTURE SUSPEND
LET S = NPT*FPPF(.90,NPT,NP)
LET S = SQRT(S)
LET JOINTSU = YNEW + S*YPREDS
LET JOINTSL = YNEW - S*YPREDS
CAPTURE RESUME
PRINT " "
PRINT "90% SCHEFFE JOINT PREDICTION INTERVALS FOR NEW VALUES"
PRINT JOINTSL YNEW JOINTSU
CAPTURE SUSPEND
.
. Step 6: Plot various diagnostic statistics
.
. Derive Cook's V statistic and Mahalanobis distance
.
LET V = (PREDSD**2)/(RESSD**2)
LET MAHAL = ((HII-1/N)/(1-HII))*(N*(N-2)/(N-1))
LET HBAR = P/N
LET DUMMY = SUM HII
SET WRITE FORMAT 5F10.5
CAPTURE RESUME
PRINT " "
PRINT " HII COOK DFFITS V MAHAL"
PRINT HII COOK DFFITS V MAHAL
CAPTURE SUSPEND
SET WRITE FORMAT
.
. Step 6b: Plot various diagnostic statistics
.
. Plot various residuals
.
X1LABEL
XLIMITS 0 15
MAJOR XTIC MARK NUMBER 4
XTIC OFFSET 0 1
MULTIPLOT 2 2
TITLE STANDARDIZED RESIDUALS
PLOT STDRES
TITLE INTERNALLY STUDENTIZED RESIDUALS
PLOT STUDRES
TITLE DELETED RESIDUALS
X1LABEL PRESS STATISTIC = ^PRESSP
PLOT DELRES
X1LABEL
TITLE EXTERNALLY STUDENTIZED RESIDUALS
PLOT ESTUDRES
END OF MULTIPLOT
.
. Plot several diagnotic statistics
.
.
MULTIPLOT 2 2
CHARACTER FILL ON OFF
CHARACTER CIRCLE BLANK
LINE BLANK SOLID DOTTED
TITLE PLOT OF LEVERAGE POINTS
Y1LABEL
X1LABEL DOTTED LINE AT 2*AVERAGE LEVERAGE
YTIC OFFSET 0 0.1
LET TEMP6 = DATA 1 N
LET DUMMY = 2*HBAR
LET TEMP4 = DATA DUMMY DUMMY
LET TEMP5 = DATA HBAR HBAR
SPIKE ON
SPIKE BASE HBAR
SPIKE LINE DOTTED
.
PLOT HII AND
PLOT TEMP4 TEMP5 VS TEMP6
SPIKE OFF
YTIC OFFSET 0 0
.
CHARACTER CIRCLE BLANK BLANK
LINE BLANK DOTTED DOTTED
Y1LABEL
X1LABEL DOTTED LINES AT 1 AND 2*SQRT(P/N)
LET TEMP4 = DATA 1 1
LET DUMMY = 2*SQRT(P/N)
LET TEMP5 = DATA DUMMY DUMMY
TITLE PLOT OF DFFITS POINTS
.
PLOT DFFITS AND
PLOT TEMP4 TEMP5 VS TEMP6
.
X1LABEL DOTTED LINES AT 20 AND 50TH PERCENTILES OF F DISTRIBUTION
LET DUMMY = FPPF(.20,P,NP)
LET TEMP4 = DATA DUMMY DUMMY
LET DUMMY = FPPF(.50,P,NP)
LET TEMP5 = DATA DUMMY DUMMY
TITLE PLOT OF COOK'S DISTANCE
.
PLOT COOK AND
PLOT TEMP4 TEMP5 VS TEMP6
.
X1LABEL
TITLE PLOT OF MAHALANOBIS DISTANCE
PLOT MAHAL
.
END OF MULTIPLOT
.
. Step 6c: Calculate:
.
. 1. Catcher matrix
. 2. Variance inflation factors
. 3. Condition numbers of X'X (based on singular
. values of scaled X)
. 4. Partial regression plots (also called added variable plots)
. 5. Partial leverage plots
. 6. DFBETA'S
.
LET XMAT = CREATE MATRIX X1 X2 X3
LET C = CATCHER MATRIX XMAT
LET VIF = VARIANCE INFLATION FACTORS XMAT
LET RJ = 0 FOR I = 1 1 NP
LET RJ = 1 - (1/VIF) SUBSET VIF > 0
LET TOL = 1/VIF SUBSET VIF > 0
LET DCOND = CONDITION INDICES XMAT
CAPTURE RESUME
PRINT " "
PRINT " "
PRINT " CONDITION"
PRINT " Rj-SQUARE VIF TOLERANCE INDICES"
SET WRITE FORMAT 5X,F5.3,F10.5,F12.5,F10.5
PRINT RJ VIF TOL DCOND
CAPTURE SUSPEND
.
MULTIPLOT 2 2
CHARACTER CIRCLE
LINE BLANK
SPIKE BLANK
LIMITS DEFAULT
TIC OFFSET 0 0
MAJOR TIC MARK NUMBER DEFAULT
.
LOOP FOR K = 2 1 P
TITLE Partial Regression Plot for X^K
PARTIAL REGRESSION PLOT Y X2 X3 X^K
.
TITLE PARTIAL LEVERAGE FOR X^K
PARTIAL LEVERAGE PLOT Y X2 X3 X^K
.
LET DUMMY = XTXINV^K(K)
LET DFBETA^K = (C^K*ESTUDRES)/SQRT(DUMMY*(1-HII))
END OF LOOP
END OF MULTIPLOT
.
LET DUMMY = XTXINV1(1)
TITLE PLOT OF DFBETA'S (B0, B1, B2)
LINE BLANK ALL
CHARACTER B0 B1 B2
CHARACTER SIZE 2 ALL
LET TEMP4 = SEQUENCE 1 1 N
LET DFBETA1 = (C1*ESTUDRES)/SQRT(DUMMY*(1-HII))
PLOT DFBETA1 DFBETA2 DFBETA3 VS TEMP4
Date created: 09/02/2021 |
Last updated: 12/04/2023 Please email comments on this WWW page to alan.heckert@nist.gov. | ||||||||||||||||||||
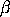 i and intercept zero.
i and intercept zero.