|
|
BOOTSTRAP FITName:
When these assumptions are at least approximately satisfied, OLS provides the optimal estimates and uncertainty intervals for the fit coefficients. However, if the assumptions are not at least approximately satisfied, then the OLS estimates may no longer be optimal (and may in fact be quite wrong). Applying transformations and weighting are common approaches to fitting when the assumptions are not satisfied. Bootstrap fitting provides an additional alternative. The bootstrap is a non-parametric method for calculating a sampling distribution for a statistic. The bootstrap calculates the statistic with N different subsamples. The subsampling is performed with replacement. In the context of fitting, we are estimating the coefficients of the fit and providing bootstrap estimates of the uncertainty. There are two approaches to bootstrapping for fitting.
Hamilton (see Reference below) gives some guidance on the contrasts between these approaches.
Given the above, if the assumption of fixed X is realistic (that is, we could readily collect new Y's with the same X values), then residual resampling is justified. For example, this would be the case in a designed experiment. However, if this assumption is not realistic (i.e., the X values vary randomly as well as the Y's), then data resampling is preferred. If the bootstrap methods produce substantially different results, this is an indication that the assumptions of fixed X and independent and identically distributed residuals may not be valid. The BOOTSTRAP FIT command produces the following output:
where <y> is the response (dependent) variable; <x1> .... <xk> is a list of one or more independent variables; and where the <SUBSET/EXCEPT/FOR qualification> is optional.
BOOTSTRAP Y X1 X2 X3 X4 BOOTSTRAP Y X1 X2 X3 X4 SUBSET TAG > 1
The default is RESIDUAL. You can use EFRON as a synonym for RESIDUAL and WU as a synonym for DATA.
BOOTSTRAP LINEAR CALIBRATION PLOT BOOTSTRAP QUADRATIC CALIBRATION PLOT The BOOTSTRAP FIT METHOD command also applies to theses commands.
The default is 100 bootstrap samples. Some sources recommend as many as 2,000 bootstrap samples for accurate confidence intervals for the parameter estimates.
Some refinements to generate more accurate confidence intervals have been proposed. The issue of bootstrap confidence intervals for multilinear fitting is discussed on pages 319-325 of Hamilton.
Hamilton (1992), "Regression with Graphics: A Second Course in Applied Statistics," Duxbury Press,
skip 25
read berger1.dat y x
.
set write decimals 5
set bootstrap fit method data
bootstrap samples 100
bootstrap fit y x
.
delete a0 a1
skip 0
set read format 2e15.7
read dpst1f.dat a0 a1
read dpst2f.dat a0sd a1sd
.
multiplot corner coordinates 0 0 100 100
multiplot scale factor 2
multiplot 2 2
.
title a0 estimate
let bmean = mean a0
let b025 = 2.5 percentile a0
let b975 = 97.5 percentile a0
let bmean = int(bmean*1000)/1000
let b025 = int(b025*1000)/1000
let b975 = int(b975*1000)/1000
x2label mean = ^bmean, b025 = ^b025, b975 = ^b975
histogram a0
title a1 estimate
let bmean = mean a1
let b025 = 2.5 percentile a1
let b975 = 97.5 percentile a1
let bmean = int(bmean*1000)/1000
let b025 = int(b025*1000)/1000
let b975 = int(b975*1000)/1000
x2label mean = ^bmean, b025 = ^b025, b975 = ^b975
histogram a1
title a0 standard deviation
let bmean = mean a0sd
let bmean = int(bmean*1000)/1000
x2label mean = ^bmean
histogram a0sd
title a1 standard deviation
let bmean = mean a1sd
let bmean = int(bmean*1000)/1000
x2label mean = ^bmean
histogram a1sd
.
end of multiplot
The BOOTSTRAP FIT command generates the following output:
Bootstrap Linear/Multilinear Fit
Number of Observations: 107
Number of Bootstrap Sample 100
Bootstrap Method: Data (Wu)
Summary Table
--------------------------------------------------------------------------------------------------
Para- Estimates From Original Fit Estimates From Bootstrap Fit
meter Coef SD Mean SD 2.5 97.5
--------------------------------------------------------------------------------------------------
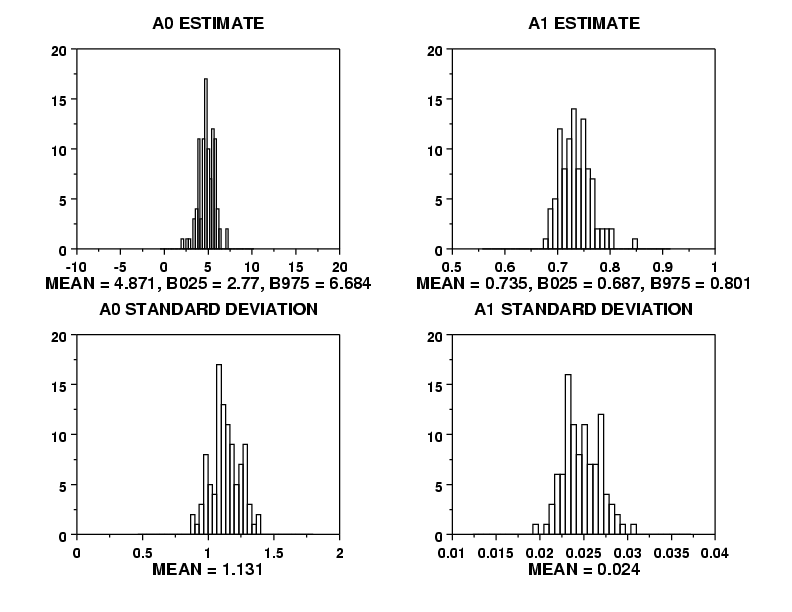
A0 4.99367 1.12565 4.87176 1.13198 2.77080 6.68491
A1 0.73111 0.02455 0.73568 0.02478 0.68731 0.80165
Histograms can be generated for the bootstrap samples of each
of the parameter estimates and the standard deviations of the
parameter estimates.
Date created: 08/12/2002 |
Last updated: 12/11/2023 Please email comments on this WWW page to [email protected]. | ||||||||||||||||||